大数据量的数据备份与恢复
一、案例1:MySQL到TIDB的逻辑备份与恢复
1、简介
迁移全量MySQL数据到TIDB。情况如下:
源库:RDS备份文件启动的MySQL实例,一个DB,数据量大约800张表,数据大小500+GB
目标库:TIDB集群
2、Navicat数据传输工具
- 直接使用Navicat的数据传输工具,配置数据源连接和目标源连接。
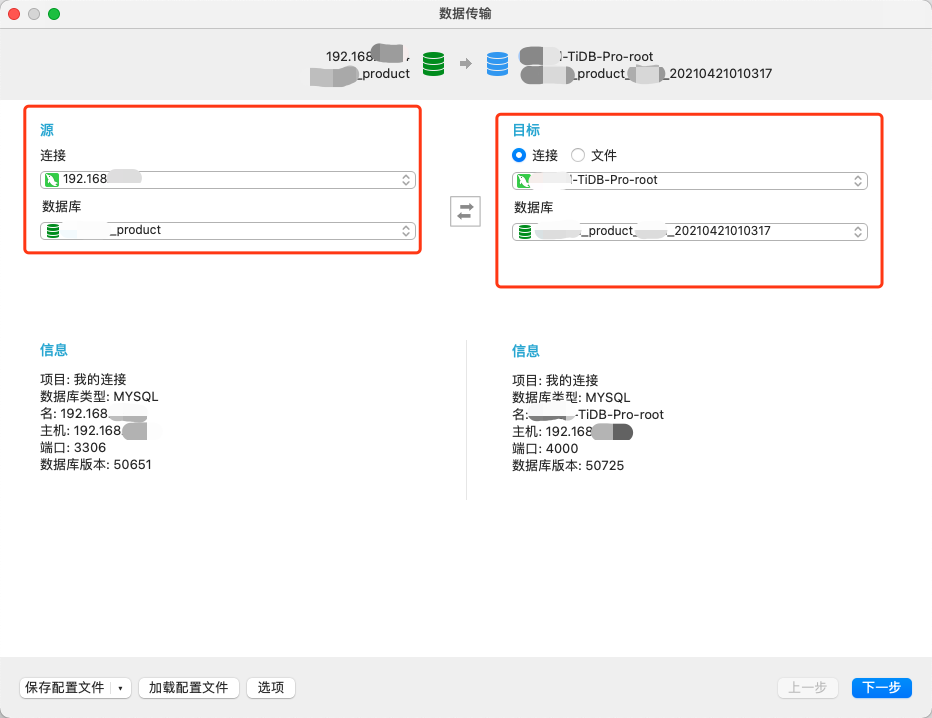
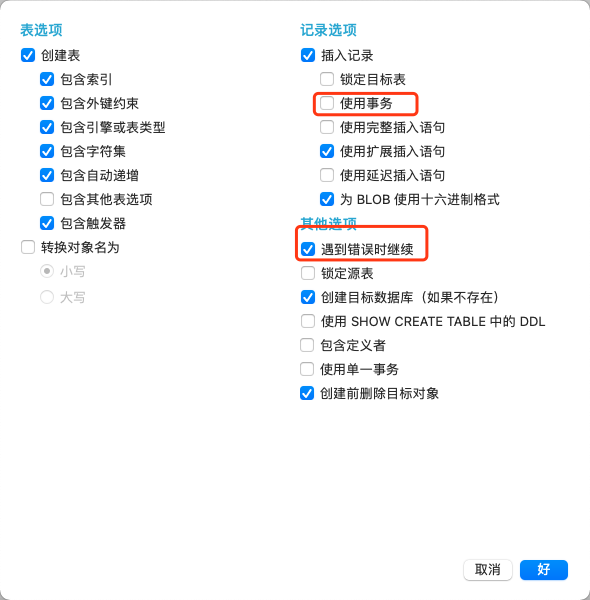
3、TiDB Dumping
- TiDB Dumping导出:导出源MySQL中的数据为SQL文件
- 修改SQL文件命名:修改TiDB Dumping导出的SQL文件命名格式
- TiDB Lighting导入:将SQL文件导入到TiDB
TiDB Dumpling
version=v4.0.5 && \
curl -# https://download.pingcap.org/tidb-toolkit-$version-linux-amd64.tar.gz | tar -zxC /opt && \
ln -s /opt/tidb-toolkit-$version-linux-amd64 /opt/tidb-toolkit-$version && \
echo "export PATH=/opt/tidb-toolkit-$version/bin:$PATH" >> /etc/profile && \
mkdir -p /data/dumping-export/sql && \
source /etc/profile && \
nohup dumpling \
-u 用于导出数据的用户 \ # 用于导出数据的用户要拥有SELECT、RELOAD、LOCK TABLES、REPLICATION CLIENT服务器权限
-p 用于导出数据的用户密码 \
-P 3306 \
-h 192.168.1.4 \
-B database \ # 指定要导出的Database
--filetype sql \ # 指定导出文件类型(可为csv/sql)
--threads 32 \ # 指定备份并发线程数
-o /data/dumping-export/sql \ # 指定导出文件存储路径
-F 256MiB \ # 指定导出文件最大大小
--logfile /data/dumping-export/export-task.log >/data/dumping-export/dumpling-nohupout.log 2>&1 &
批量修改SQL文件
# 例如源库DB为Test,想把数据导入到目标库Test-2中
old_database_name=test
new_database_name=Test-2
for i in $(ls /data/dumping-export/sql/*.sql | grep -v schema-create );do
mv /data/dumping-export/sql/$i /data/dumping-export/sql/$new_database_name.${i#*.};
done
mv /data/dumping-export/sql/${old_database_name}-schema-create.sql /data/dumping-export/sql/${new_database_name}-schema-create.sql
echo "" > ${new_database_name}-schema-create.sql
TiDB Lighting
nohup /opt/tidb-toolkit-v4.0.5-linux-amd64/bin/tidb-lightning \
-config /data/dumping-export/tidb-lightning.toml \
--log-file /data/dumping-export/import-task.log > /data/dumping-export/lightning-nohupout.log 2>&1 &
nohup tidb-lightning \
-L info \
-log-file /data/dumping-export/import-task.log \
-backend tidb \
-status-addr 10080 \
-d /data/dumping-export/sql \
-tidb-host 192.168.1.4 \
-tidb-port 4000 \
-tidb-user root \
-tidb-password ***** > /data/dumping-export/lightning-nohupout.log 2>&1 &
4、结论
大约三千万条记录的表,Navicat数据传输工具同步完耗时约3个小时,而使用TiDB Dumping耗时26分钟
二、MySQL 到 MySQL的逻辑备份与恢复
1、简介
迁移全量MySQL数据到另一个空 MySQL,进行逻辑备份与恢复。情况如下:
源库:MySQL5.6,需要同步一整个 DB中的所有表
目标库:MySQL5.6
2、方案步骤
Dumpling对源库进行逻辑备份
DB_HOST=数据库地址 DB_HOST_PORT=数据库端口 DB_USERNAME=数据库用户 DB_PASSWORD=数据库用户密码 DATE=$(date +"%Y%m%d%M") BACKUPFILE_PATH='~/Desktop' mkdir -p $BACKUPFILE_PATH/$DATE/{sql,logs} nohup dumpling \ -h ${DB_HOST} \ -P ${DB_HOST_PORT} \ -u ${DB_USERNAME} \ -p ${DB_PASSWORD} \ --filetype sql \ --threads 8 \ -B $BACKUP_DBS \ -o $BACKUPFILE_PATH/$DATE/sql \ -F 256MiB \ --logfile $BACKUPFILE_PATH/$DATE/logs/export-task.log >$BACKUPFILE_PATH/$DATE/logs/dumpling-nohupout.log 2>&1 &8并发备份64张表,共计26926007条数据,导出速率在5~11MB/s之间,落地文件大小10.06GB,总计耗时20m17.8s
整理SQL文件,使用 Navicat仅建库建表操作
MySQL 命令行执行 SQL 文件进行逻辑恢复
#!/bin/bash cd sql for file in `ls *.sql`;do db_tb_name=${file%.*} ; db=${db_tb_name%%.*} ; tabletm=${db_tb_name#*.} ; table=${tabletm%%.*}; echo "当前正在导入:库名:$db 表名:$table 文件名:$file \n" ; mysql -h 目标数据库 -uroot --database=$db -p'密码' < $file done耗时 30 分钟
三、其他
1、查询DB下所有表的行数
由于从INFORMATION_SCHEMA.TABLES中显示的表的行数不准确,需要使用count函数来统计表的行数
SELECT CONCAT( 'SELECT "', TABLE_NAME, '", COUNT(*) FROM ', TABLE_SCHEMA, '.', TABLE_NAME, ' UNION ALL' ) EXEC_SQL
FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA = 'DB名字';
上述SQL会输出用于统计表的SQL语句,复制以后,删除最后一行末尾的UNION ALL,然后执行