Cloudera 高可用及性能测试
一、HDFS NameNode高可用测试
向HDFS上传一个耗时间的大文件
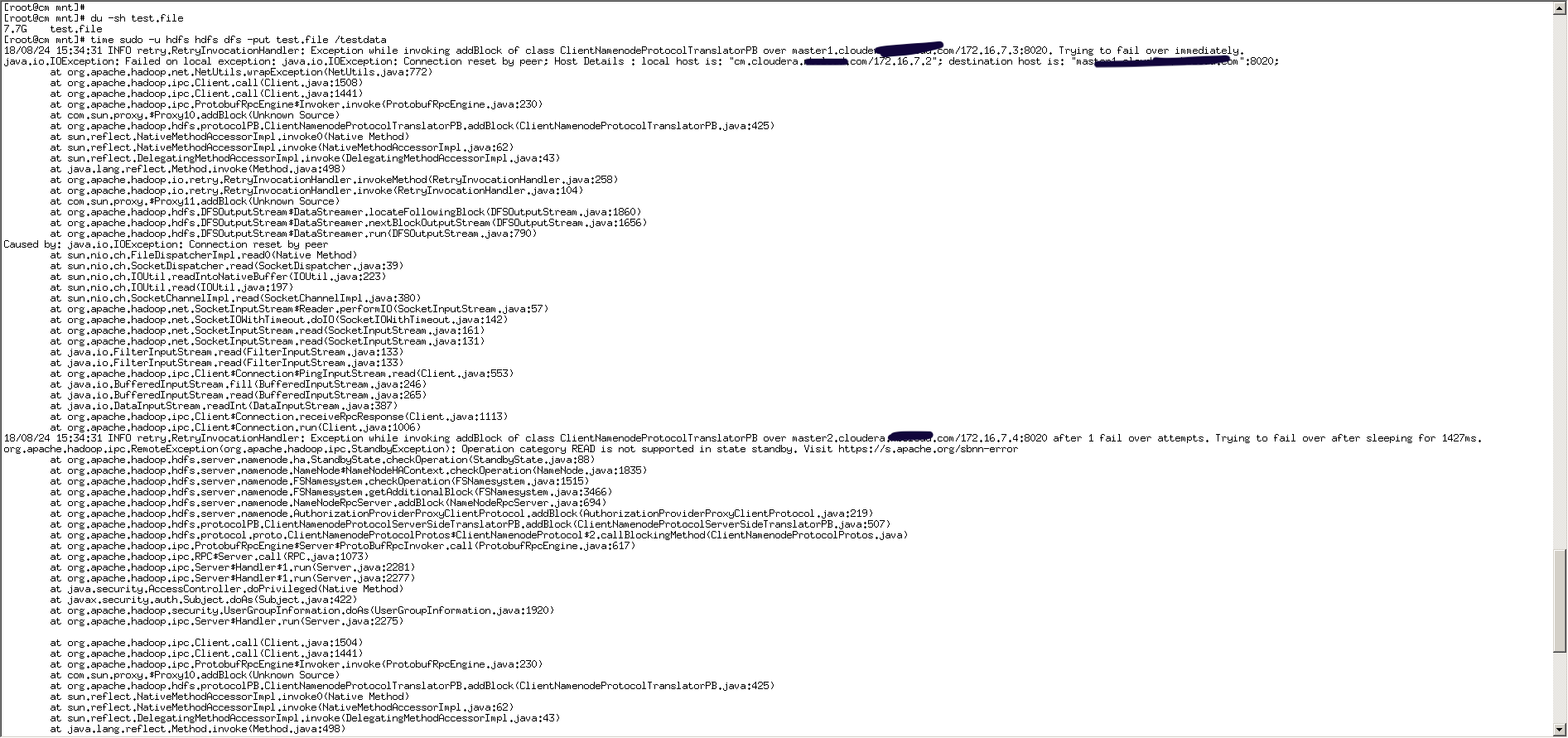
测试关闭HDFS 活动的NameNode,看备用的NameNode是否自动故障转移成为活动的主NameNode,再查看上传文件到HDFS的任务是否成功
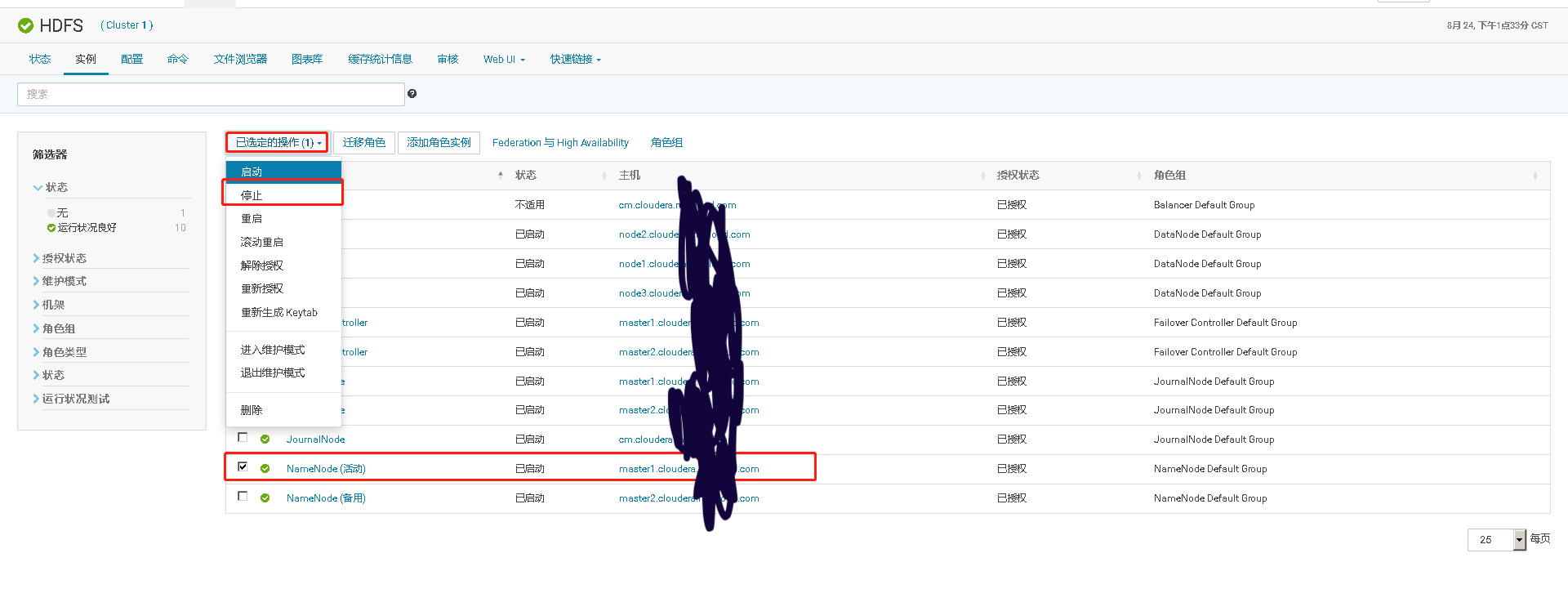
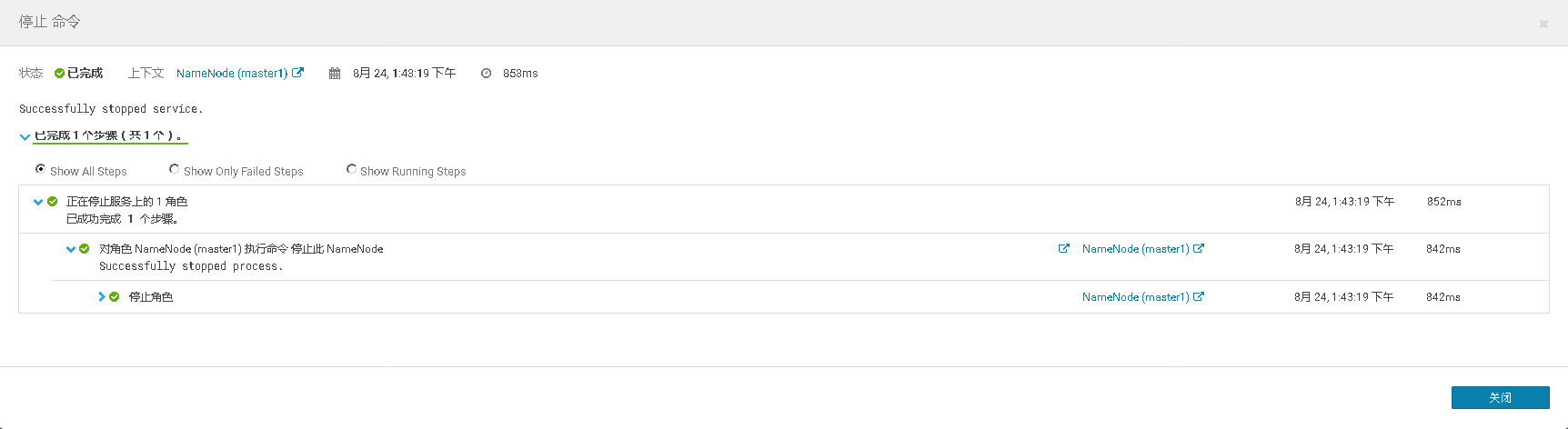
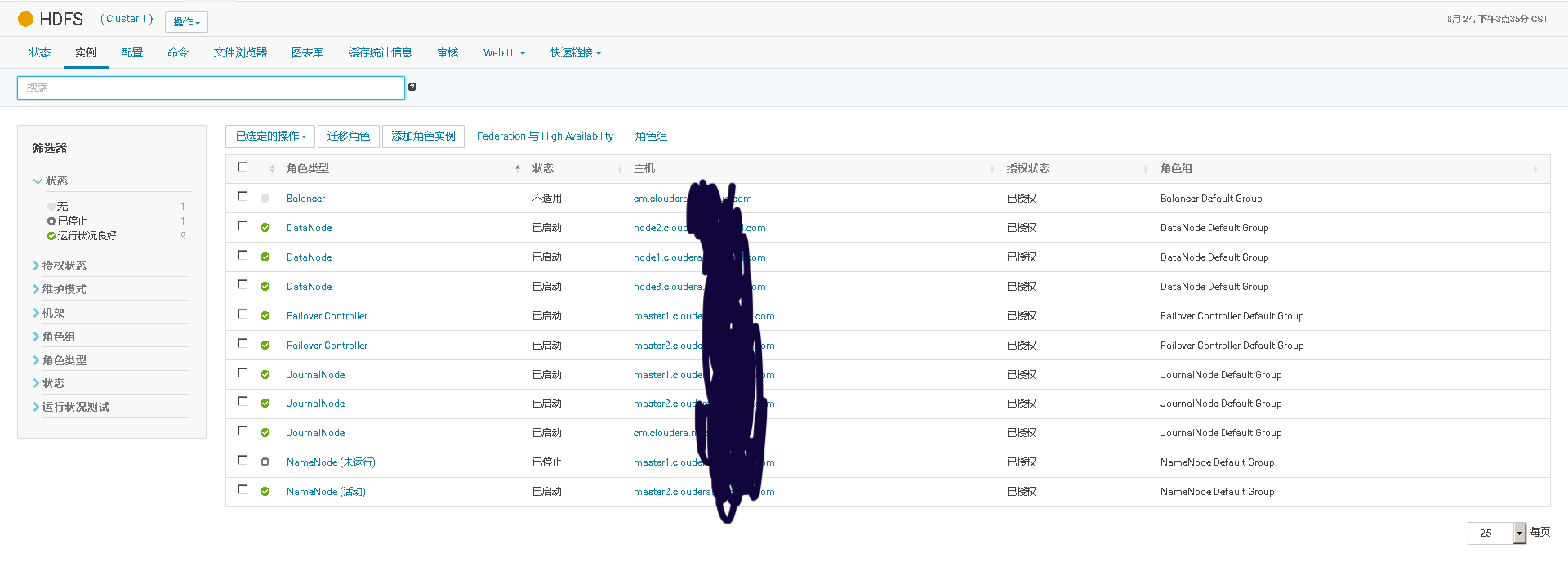
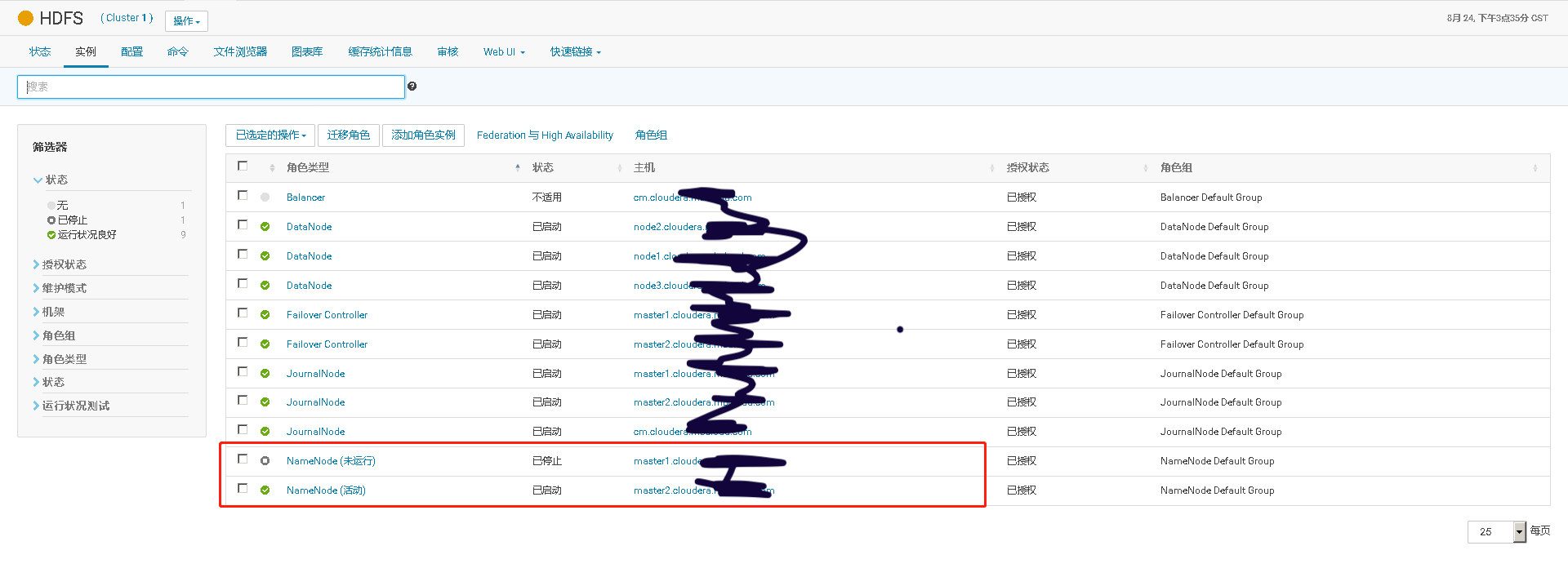
此时上传到HDFS的命令会显示原先的NameNode无法连接,但是上传任务会自动切换到新的活动的NameNode上
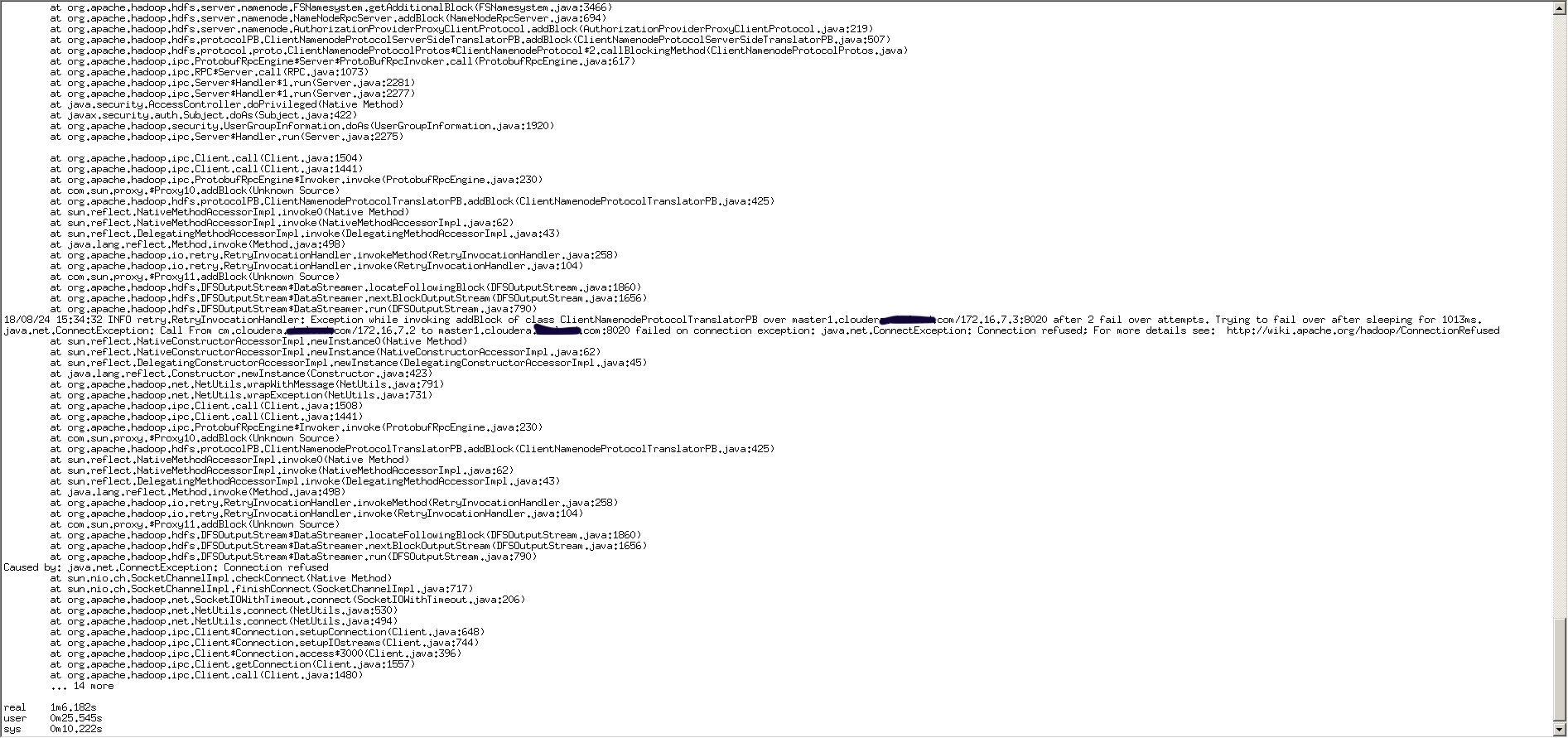
上传文件依旧成功
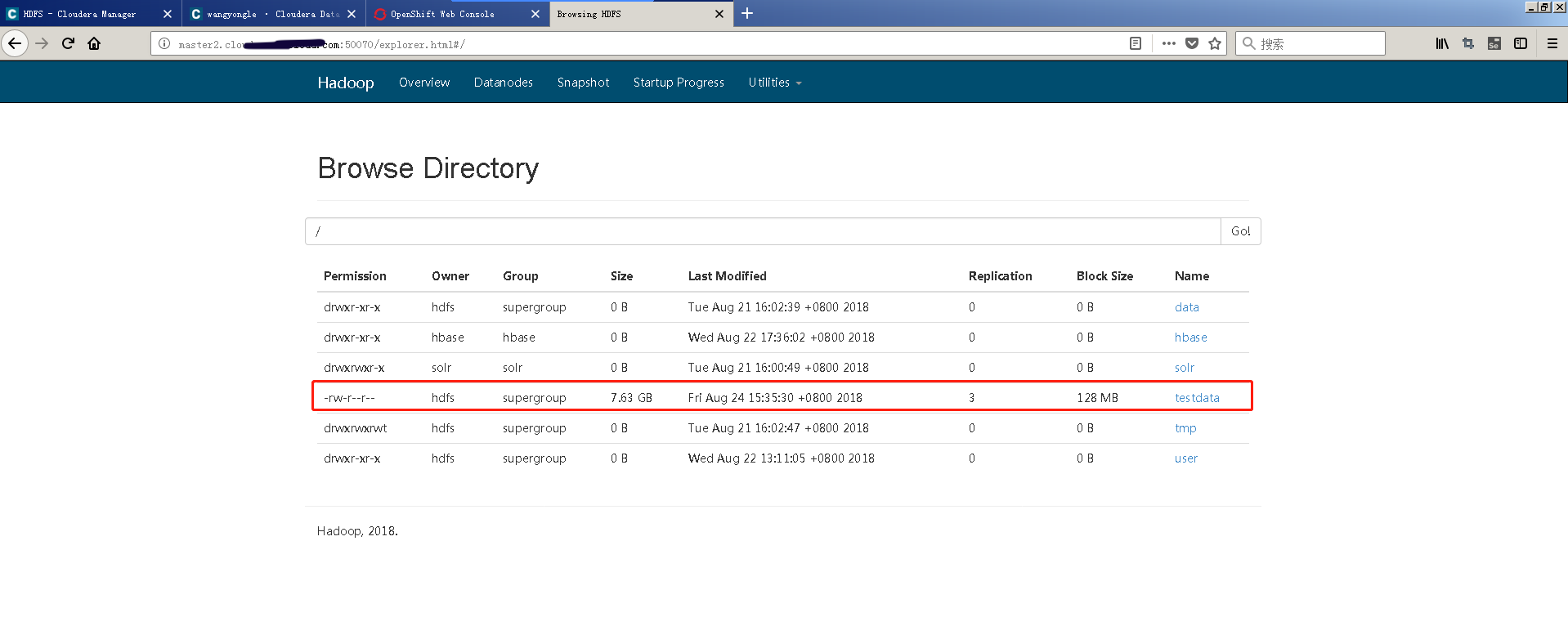
验证上传到HDFS中文件的完整性

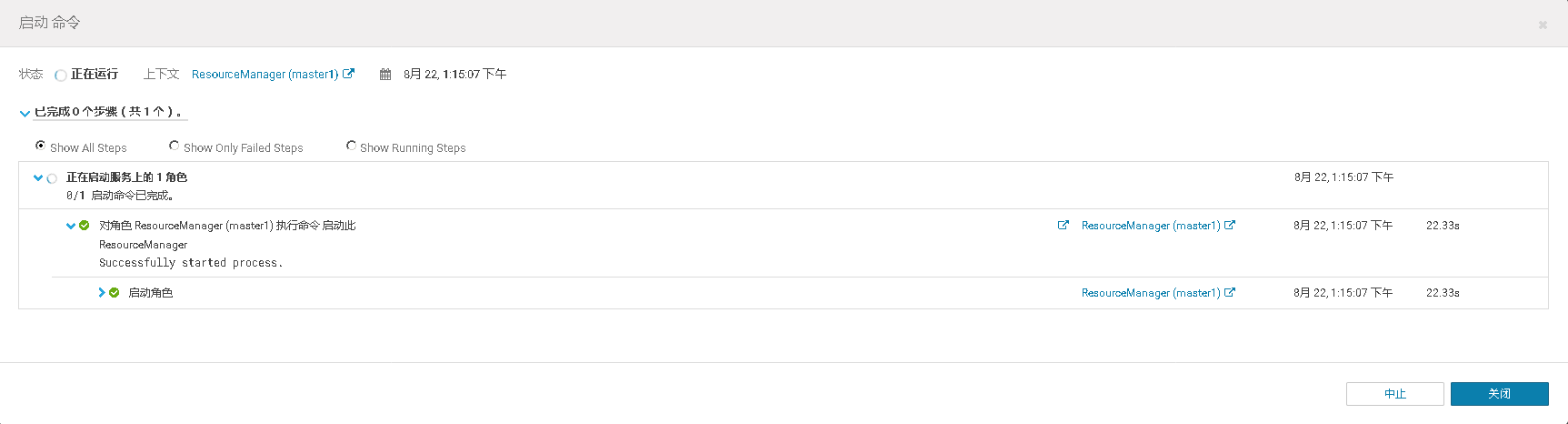
二、YARN ResourceManager高可用测试
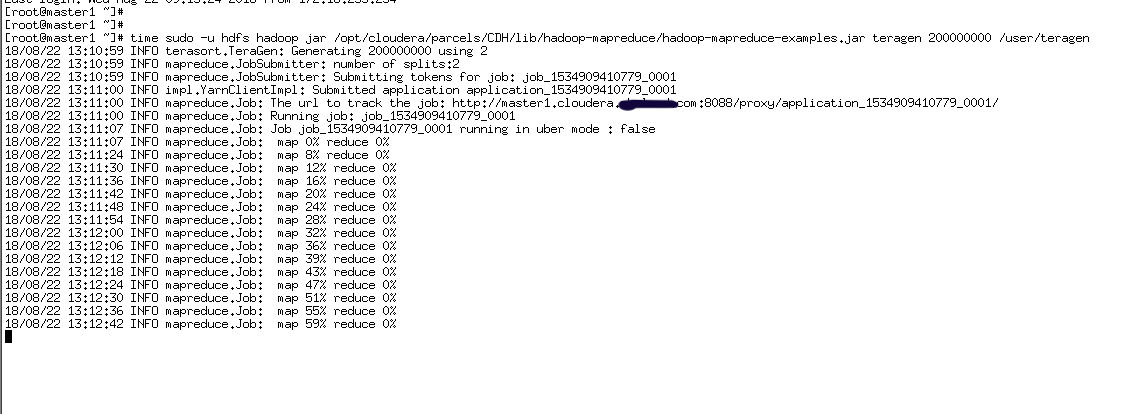
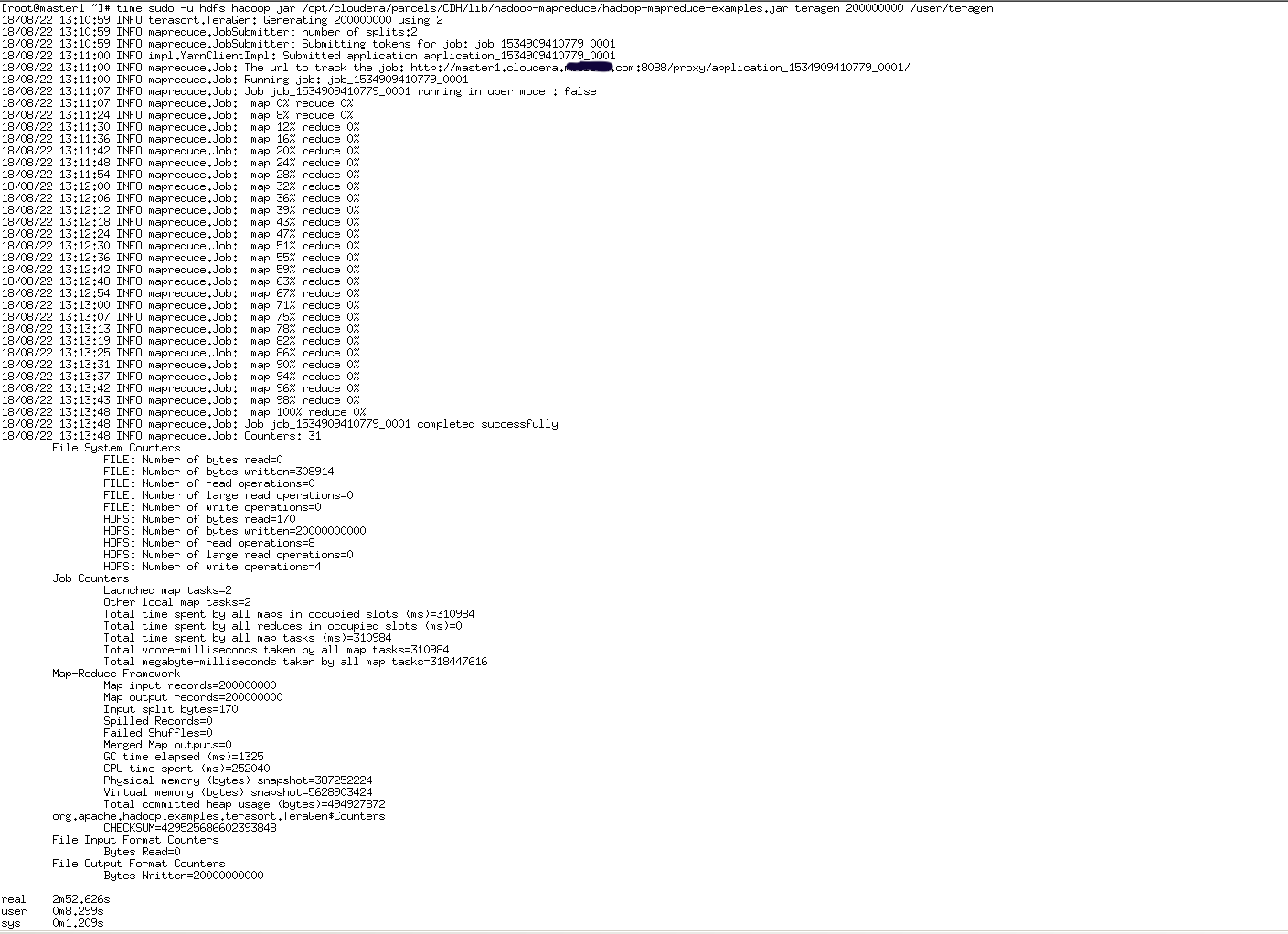
1、启动一个时间稍长的MR Job
time sudo -u hdfs hadoop jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar teragen 200000000 /user/teragen
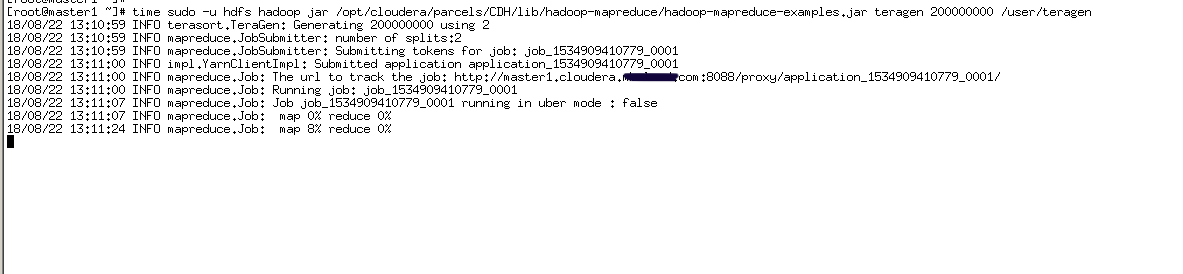
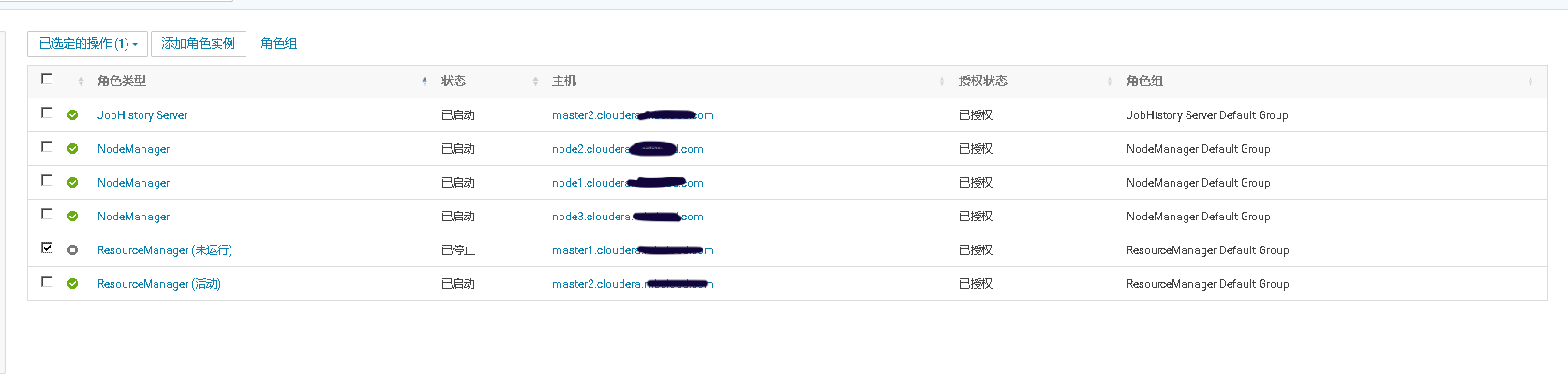
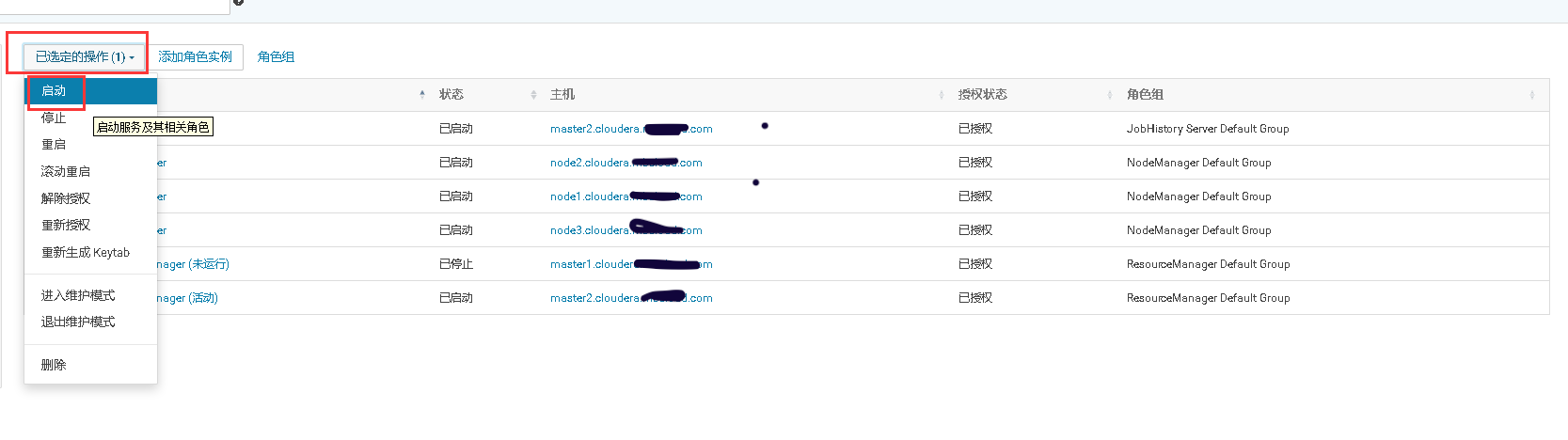
2、在MR Job任务运行时,将ResourceManager的活动节点停止,观察MR Job是否仍在运行。当MR Job任务运行完以后将关闭的ResourceManager重新启动,观察两个Resource Manager是否进行了主备切换。
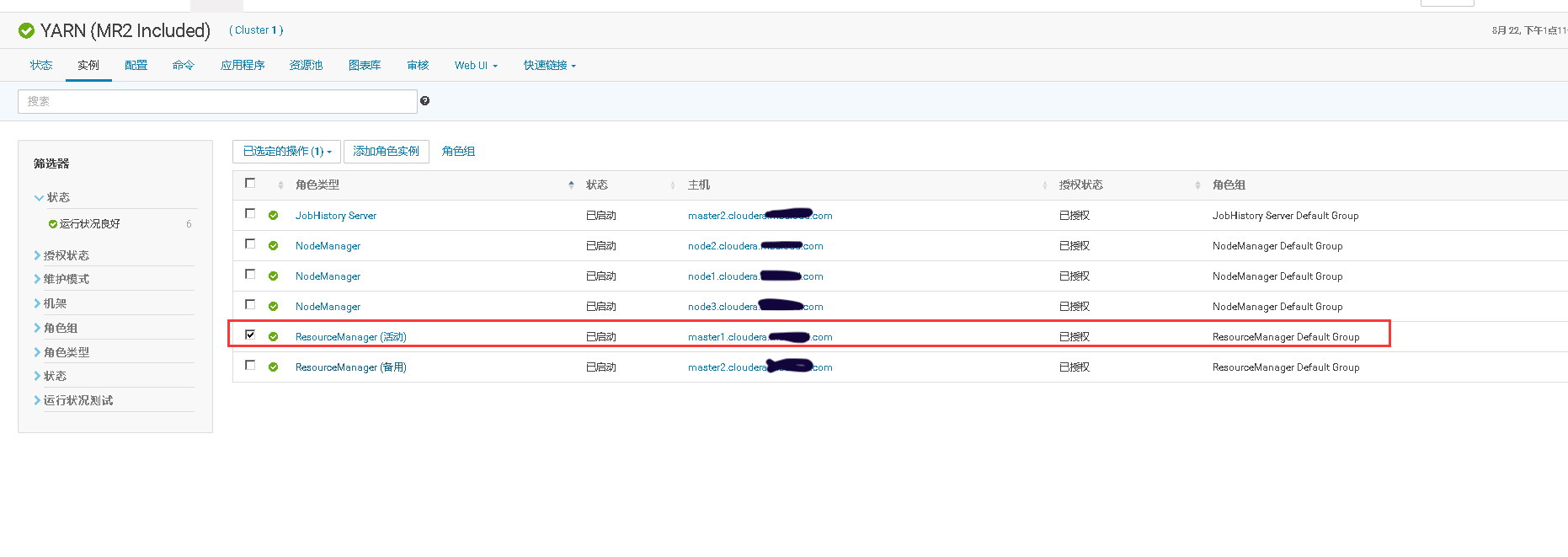
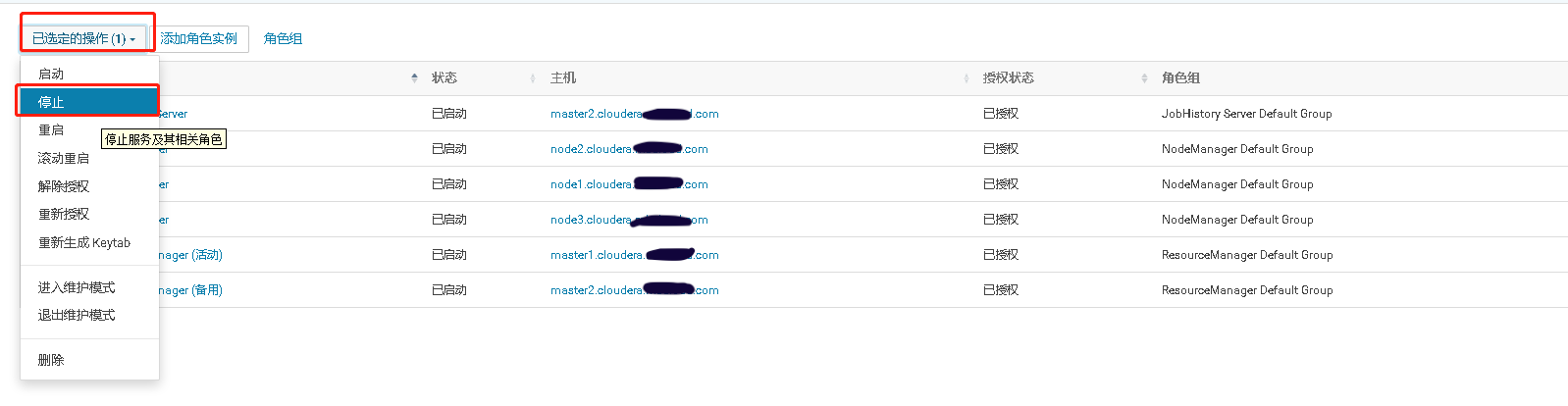
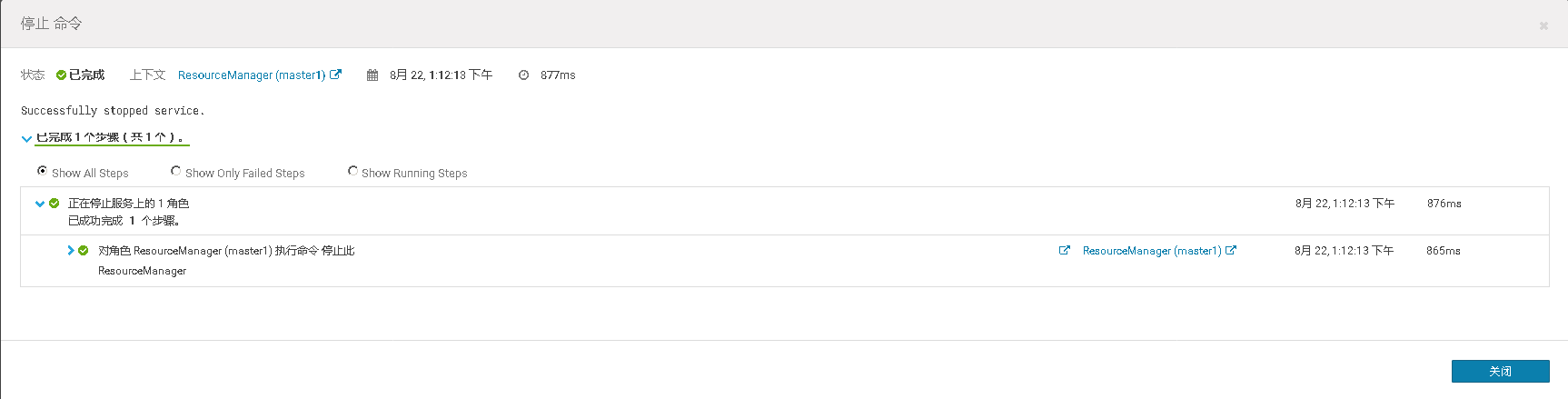
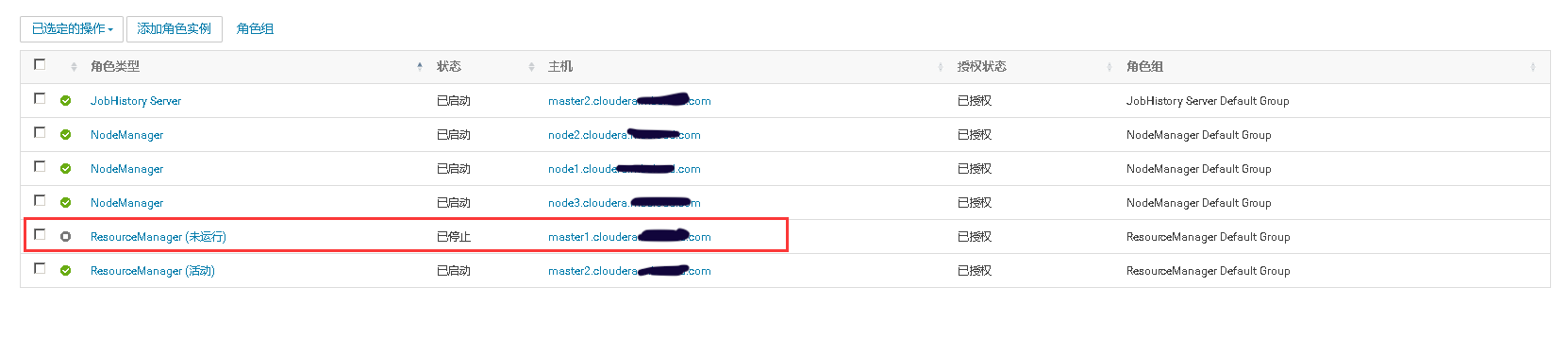
三、He Master高可用测试
测试方案:
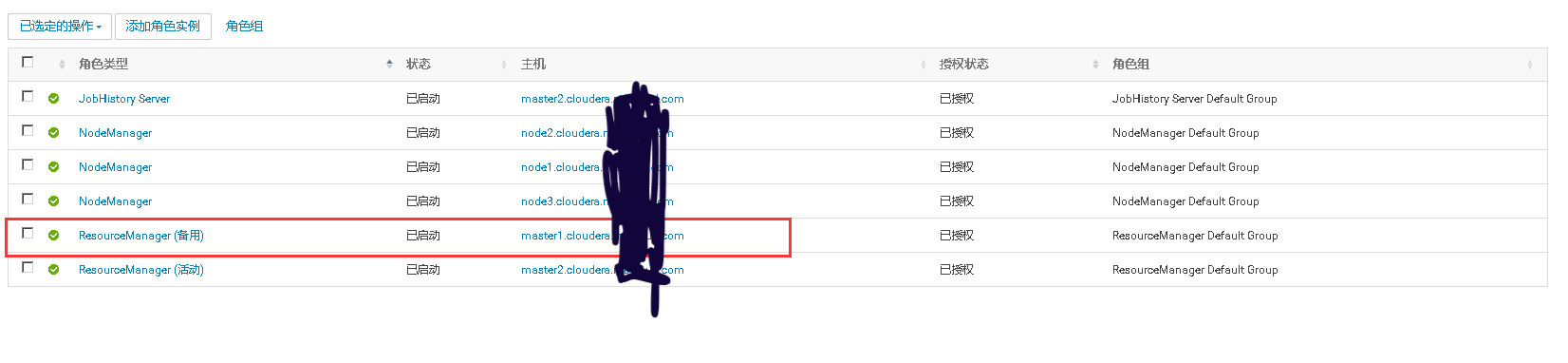
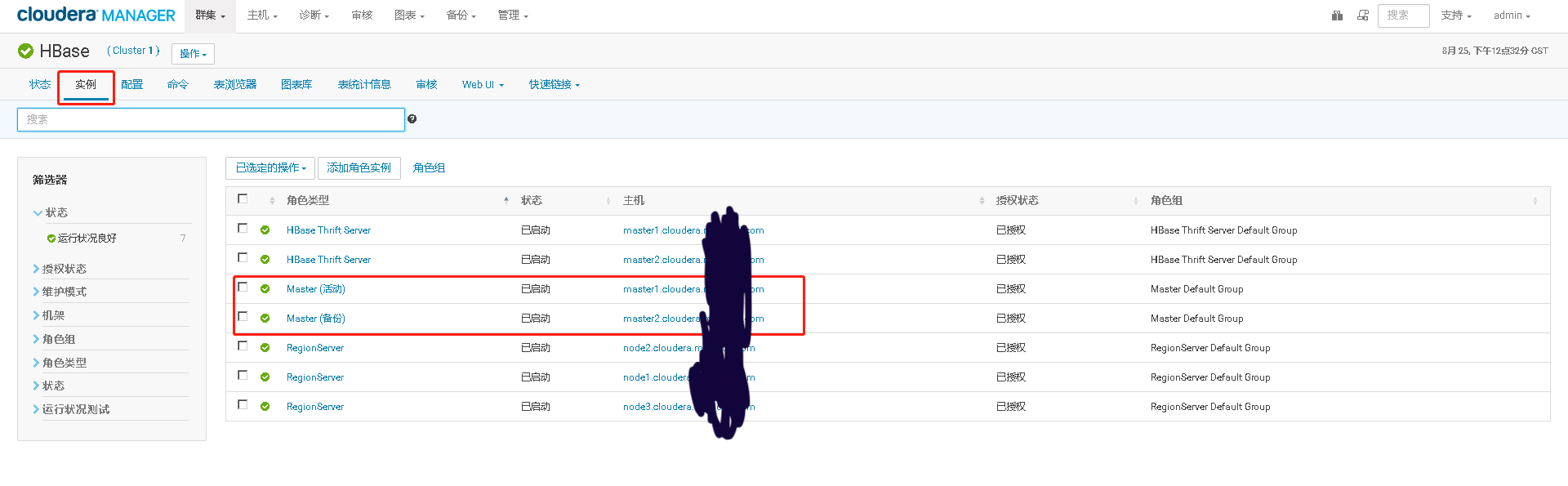
模拟用户正在向He中插入数据,此时Master的活动节点崩溃,测试He Master是否能够自动故障转移,将备用master节点转换成活动节点,继续接受用户的插入数据请求
模拟用户插入数据行为的脚本,定义为He数据的生产者
#!/bin/h
echo -e "create 'test','cf1'" | he shell -n
for i in {1..50} ;do
echo -e "put 'test','row-$i','cf1:test$x','value$i'" | he shell -n ;
sleep 1s ;
done
监控He高可用的脚本,定义为He数据的消费者
#!/bin/h
for i in {1..50} ;do
echo -e "scan 'test'" | he shell -n ;
sleep 1s ;
done

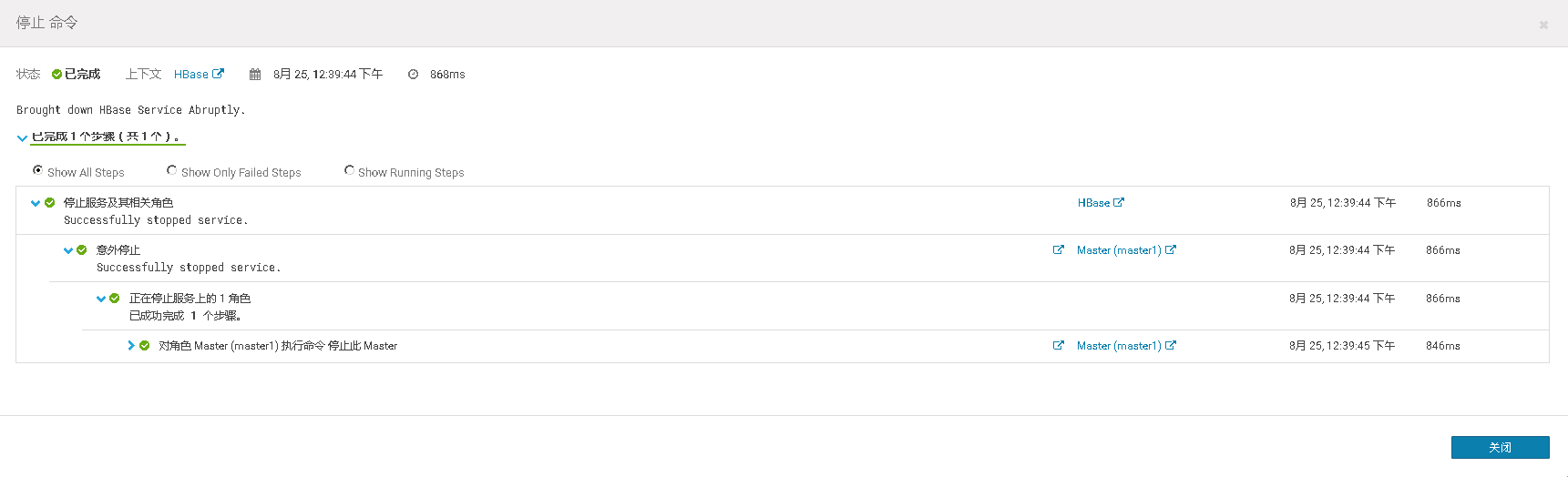
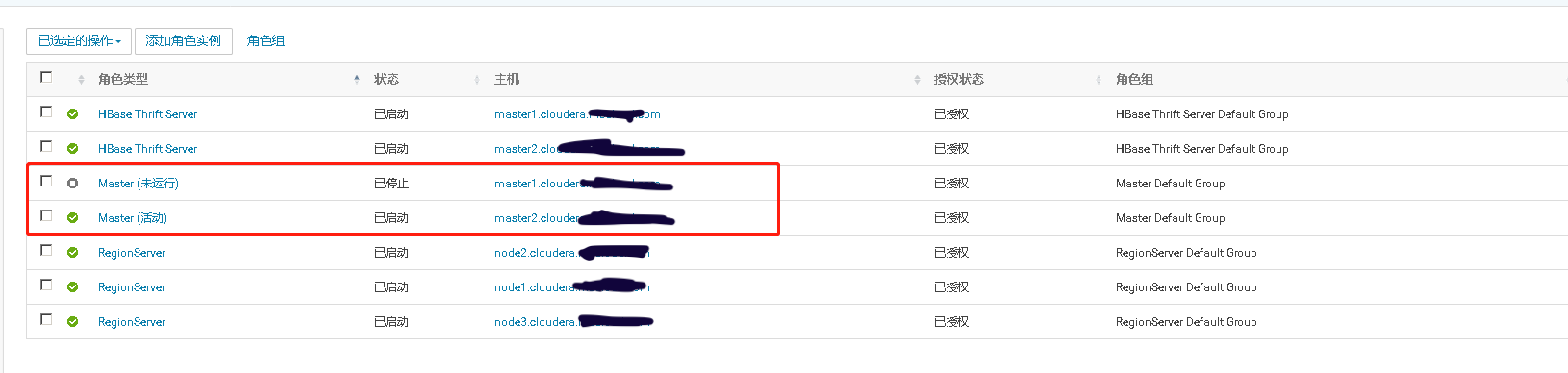
此时模拟用户插入数据的脚本仍在运行

消费者仍能监控到数据

测试完将停掉的master重新启动起来,看它是否正常还能加入he集群,成为master的一员
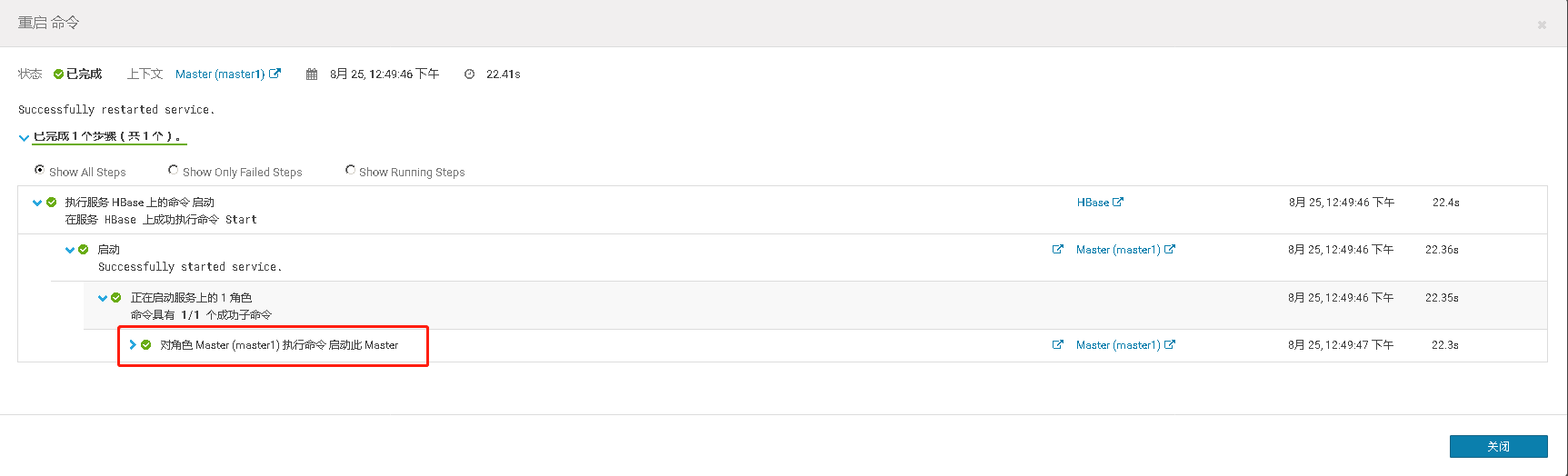
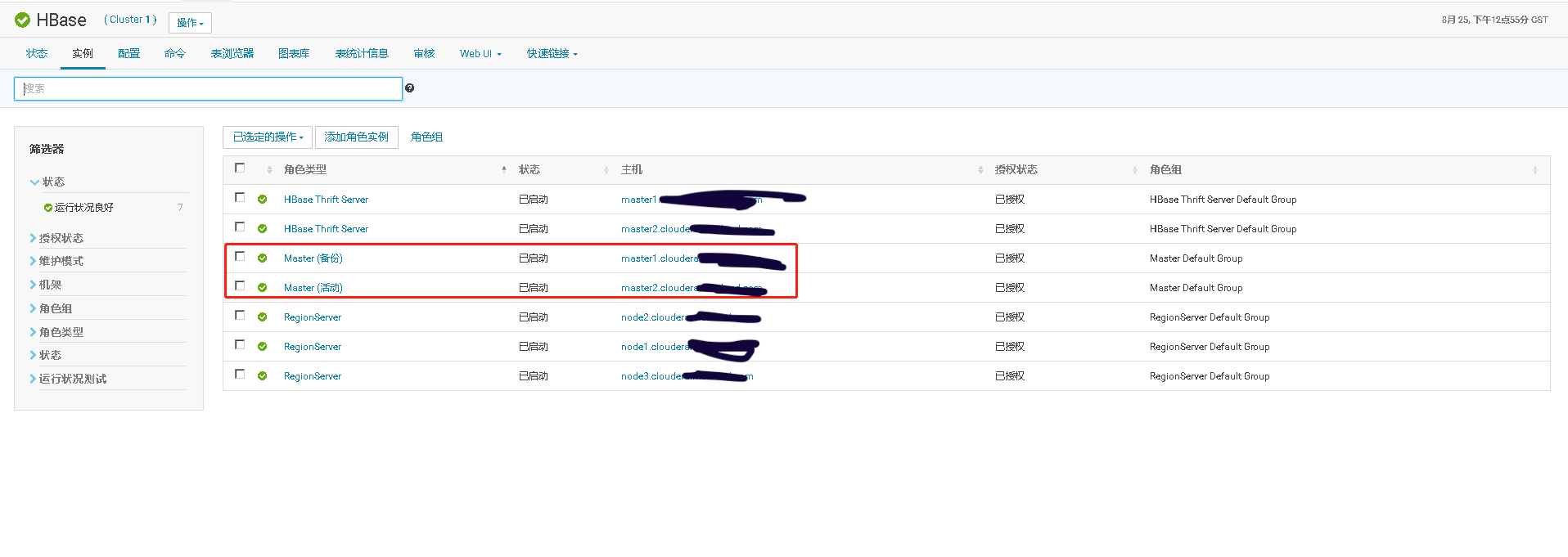
四、Hive Metastore开启高可用、并测试高可用
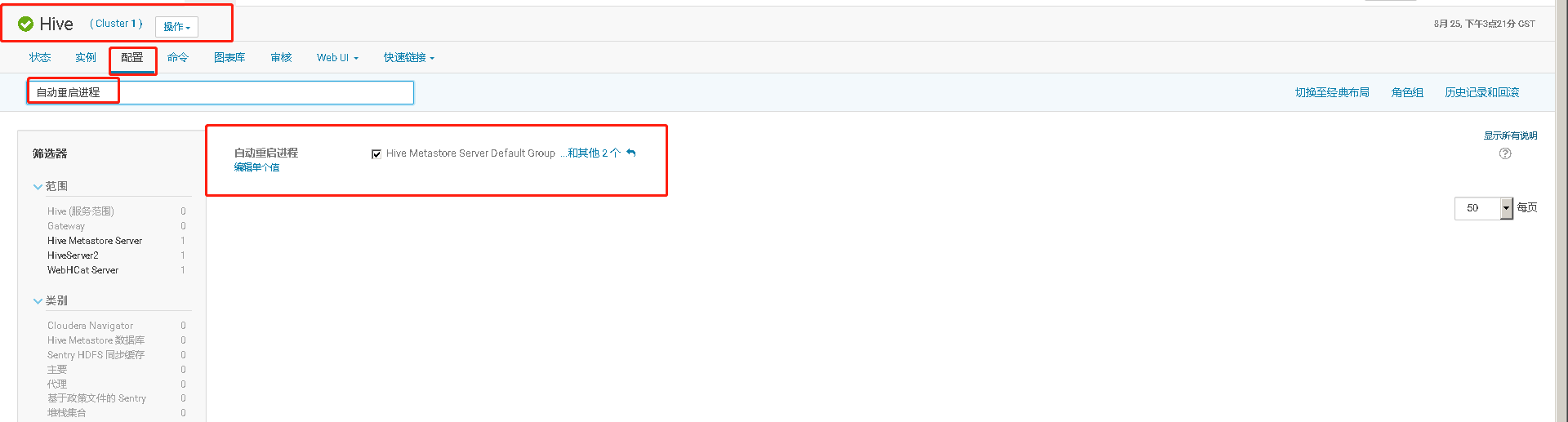
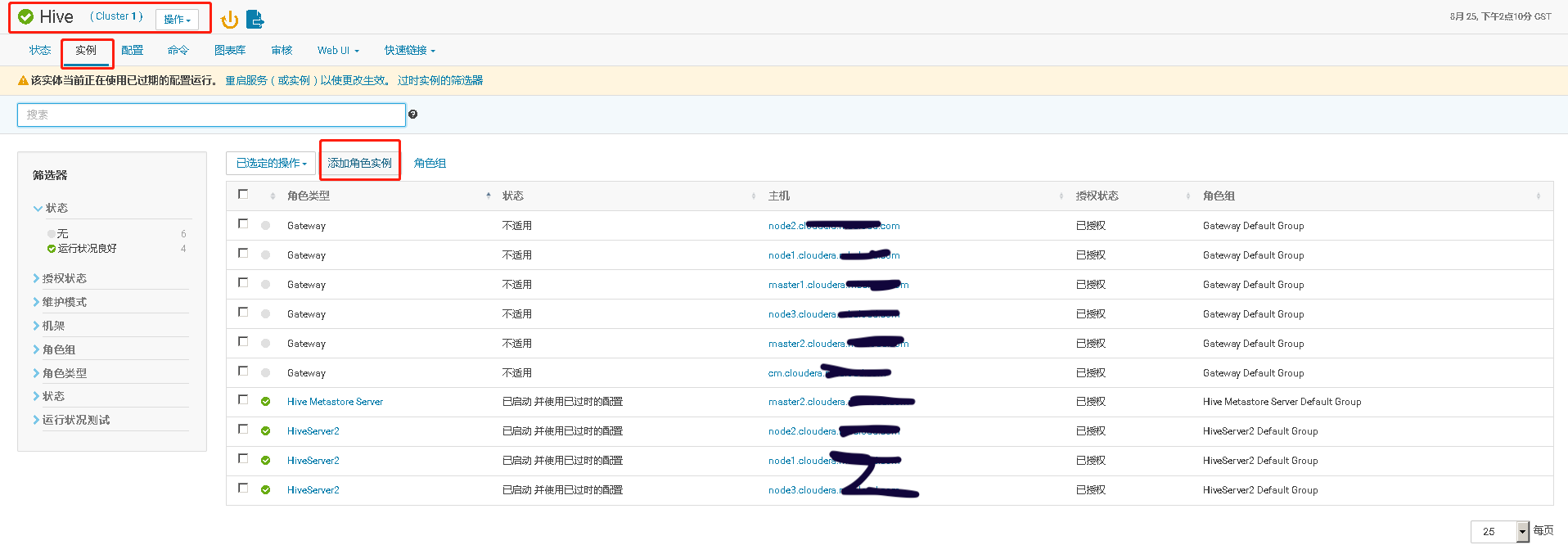
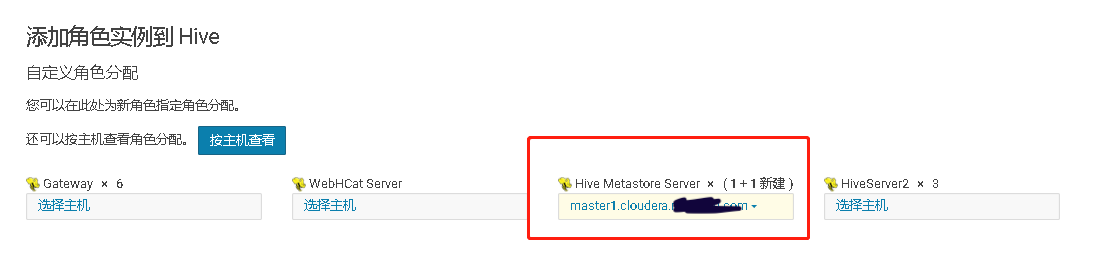
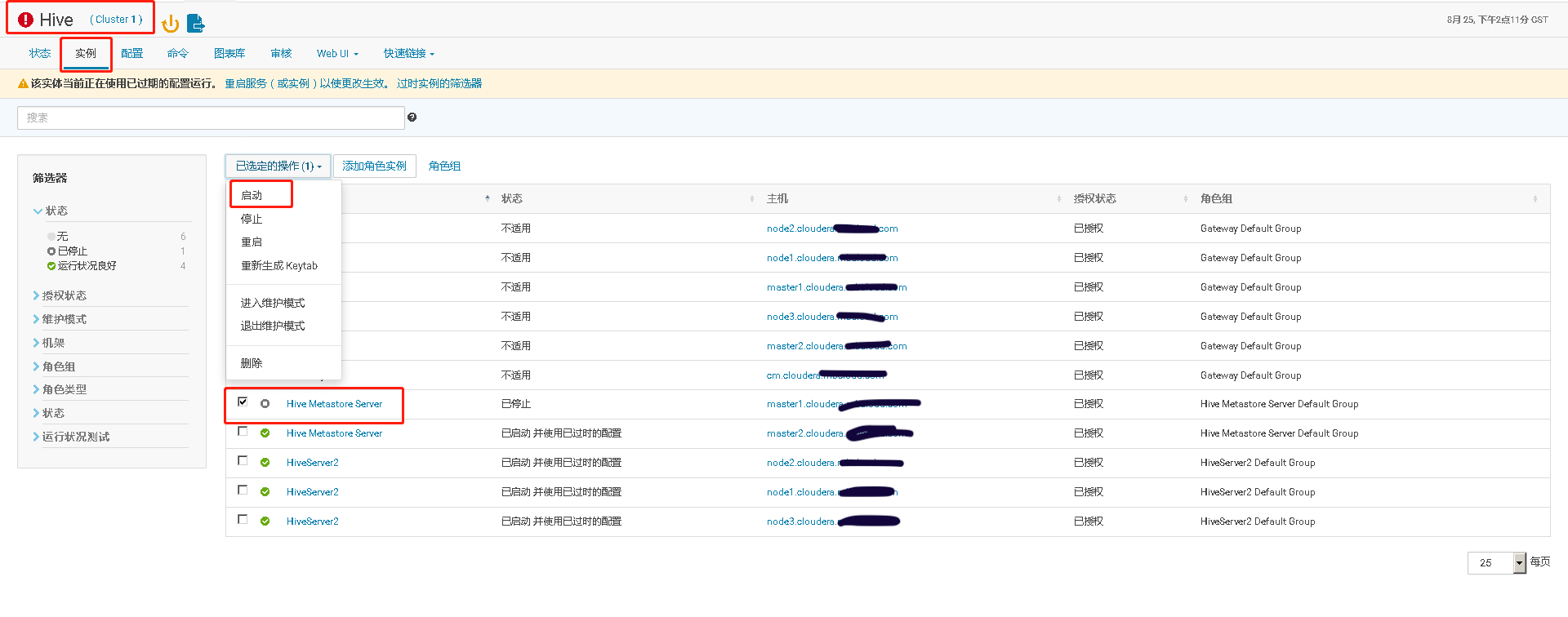
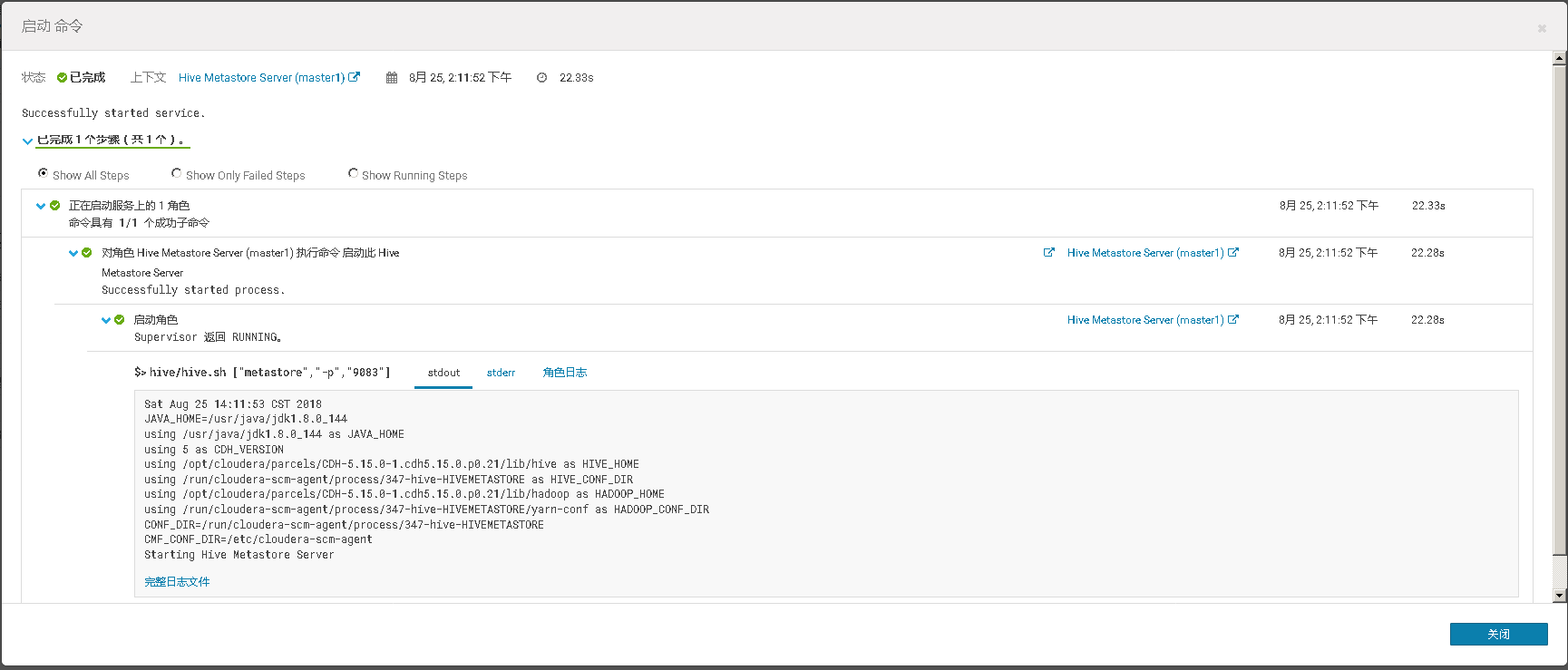
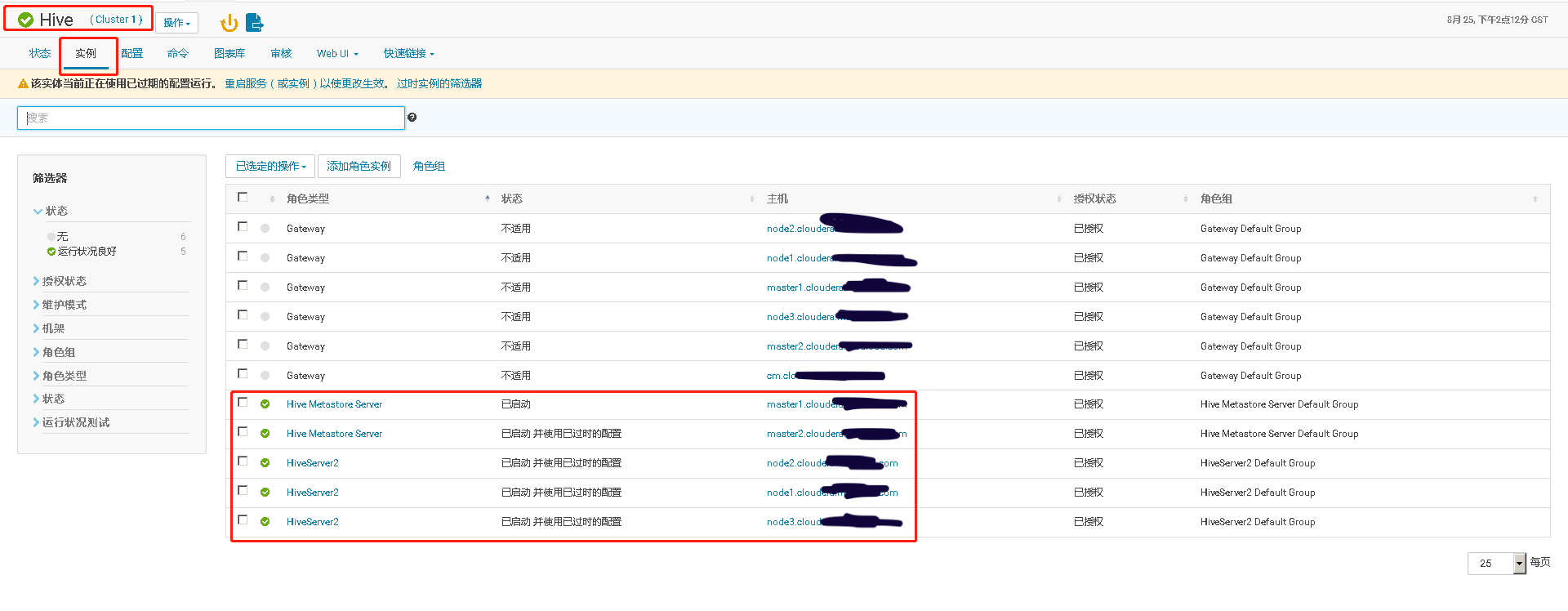
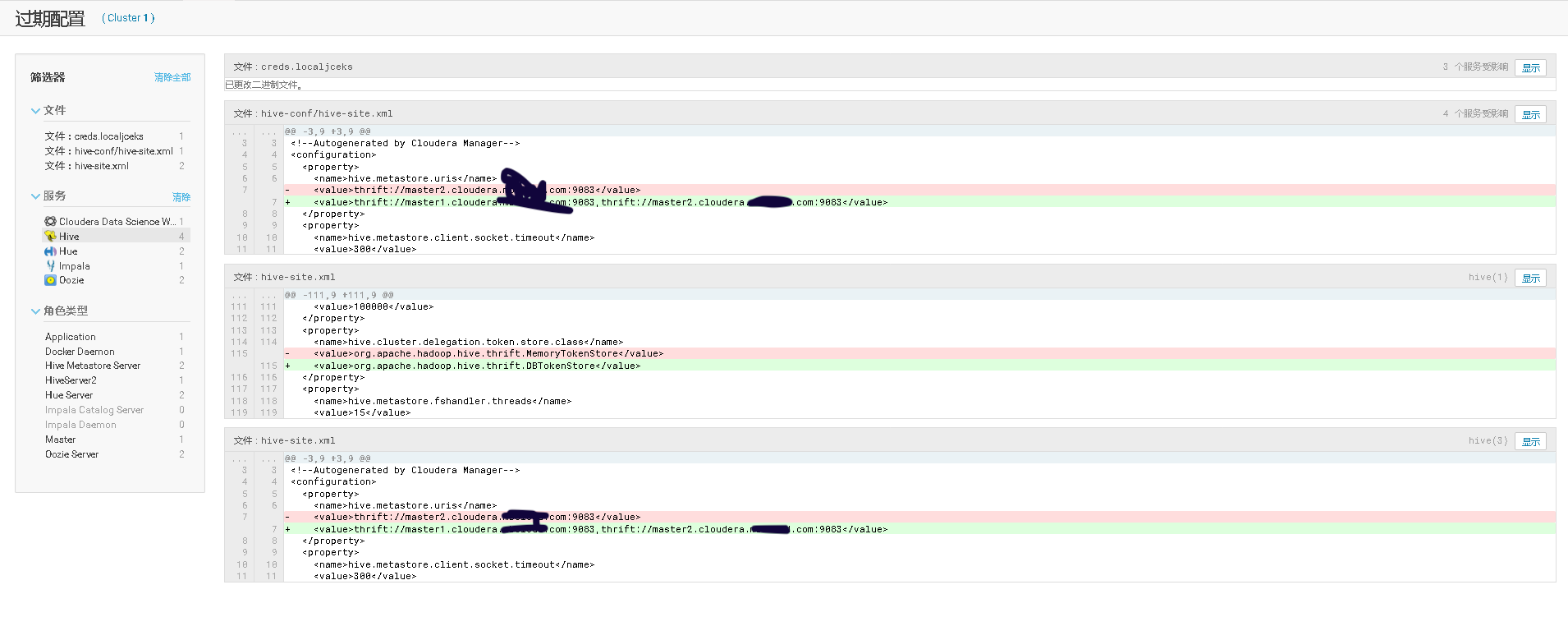

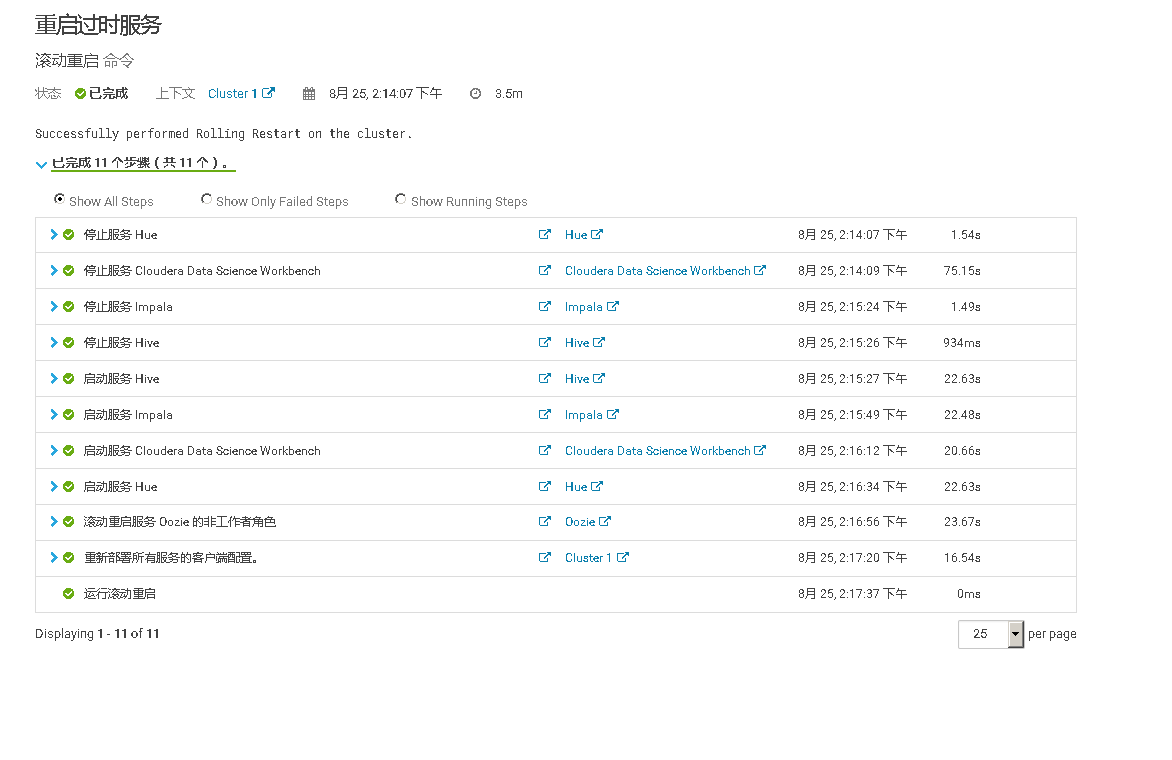
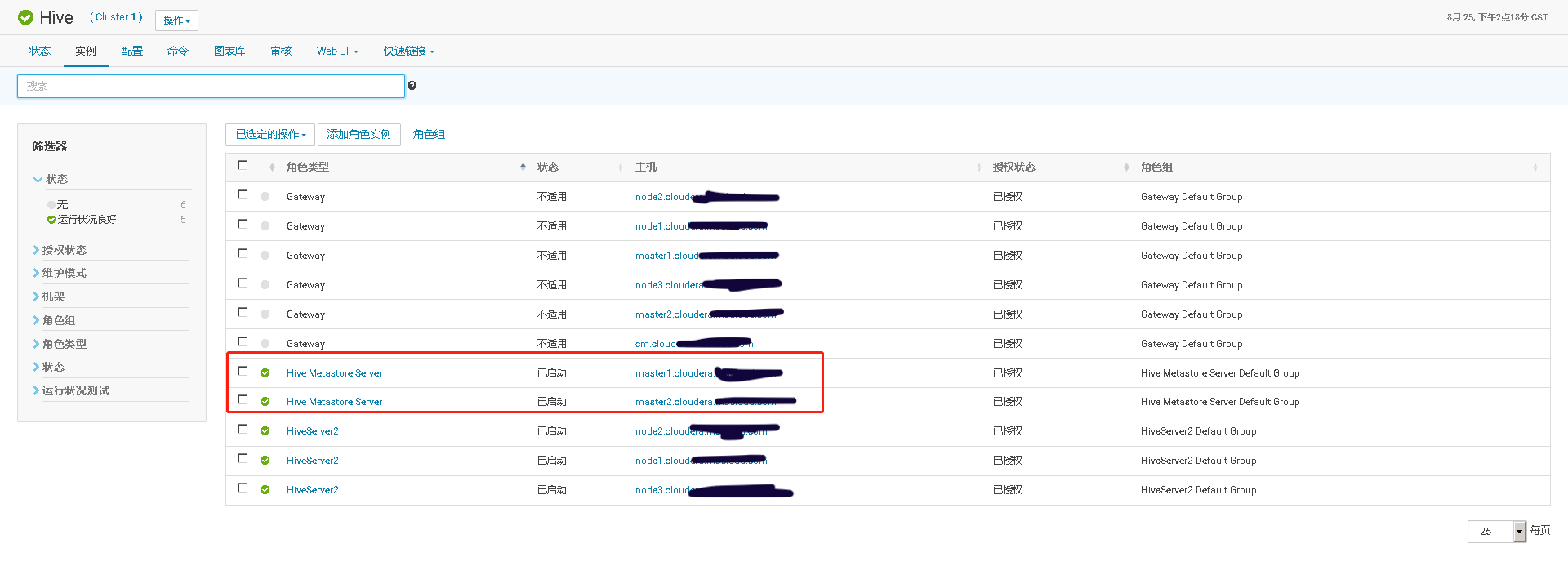
通过手工 kill 掉 Hive Metastore Server 进程,模拟进程故障,验证 Hive Metastore Server 进程自动重启的功能。

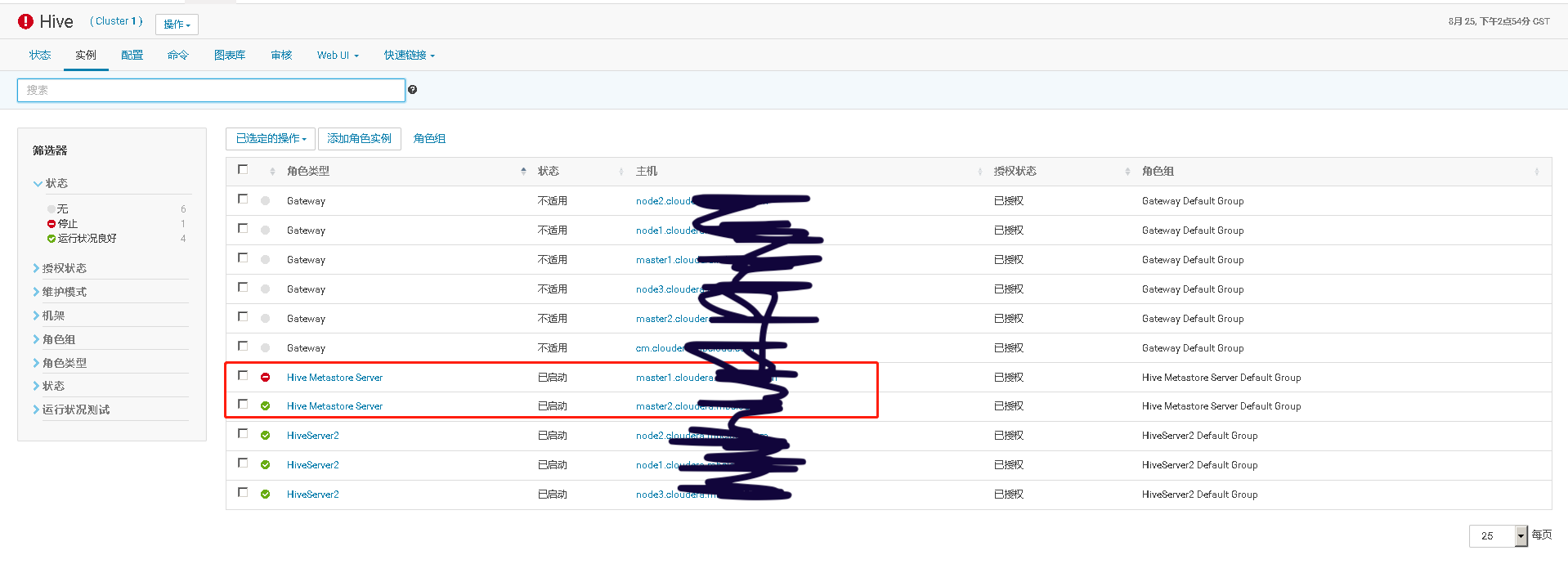
再执行 ps 命令,查看 HMS 服务情况。可以看到 agent 检测到服务异常,并调用服务启动脚本,重启服务

检查新的 HMS 服务实例的启动时间

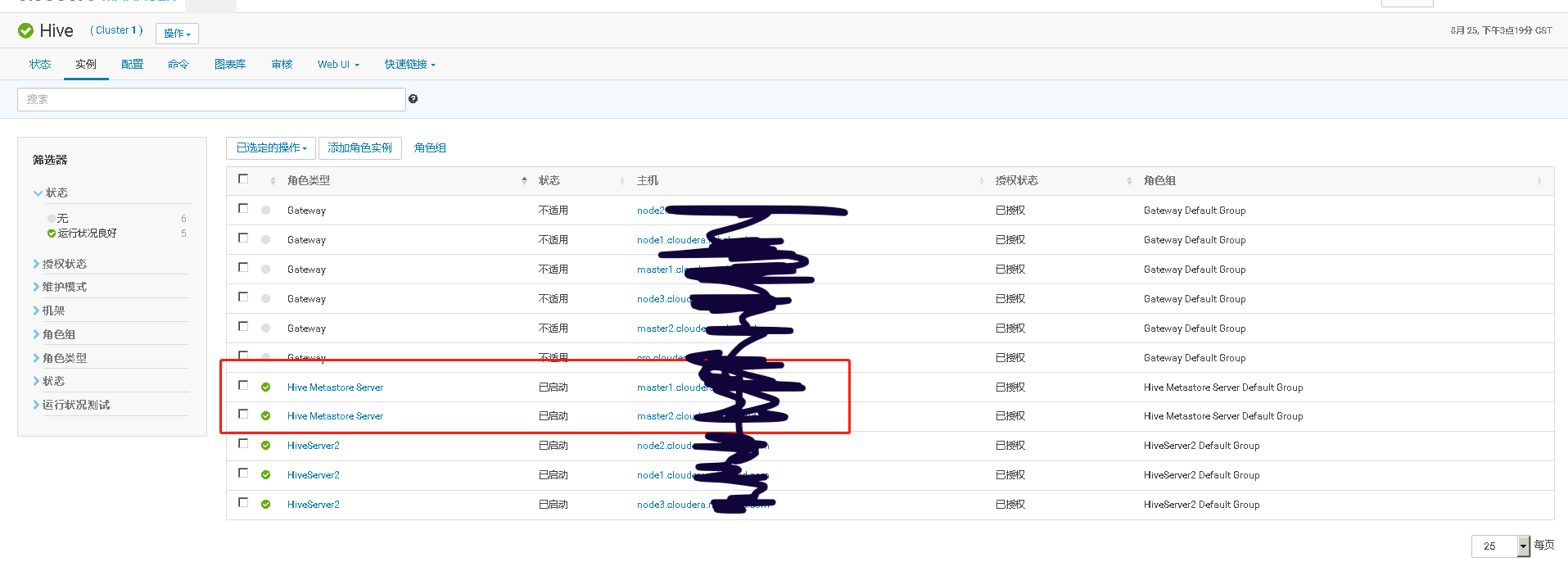
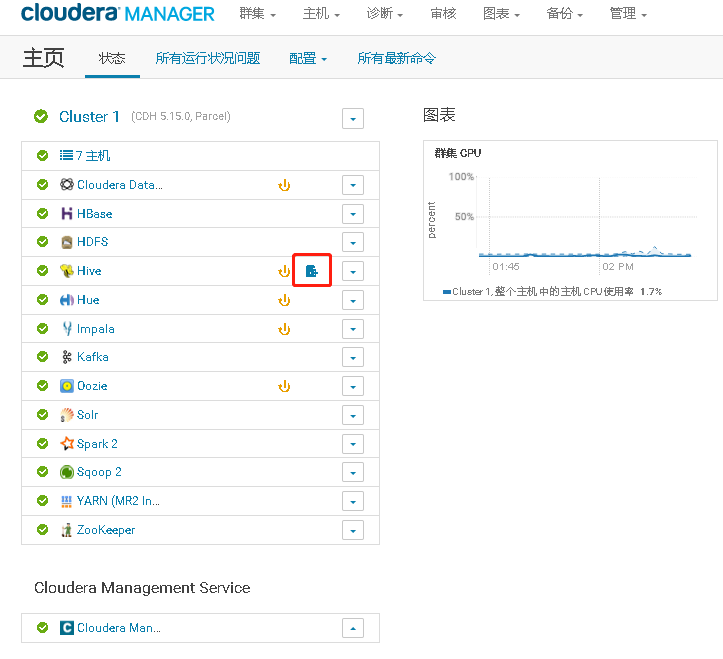
Cloudera Manager 的 Hive 服务状态页上也记录了该服务实例的异常,并产生相应的告警
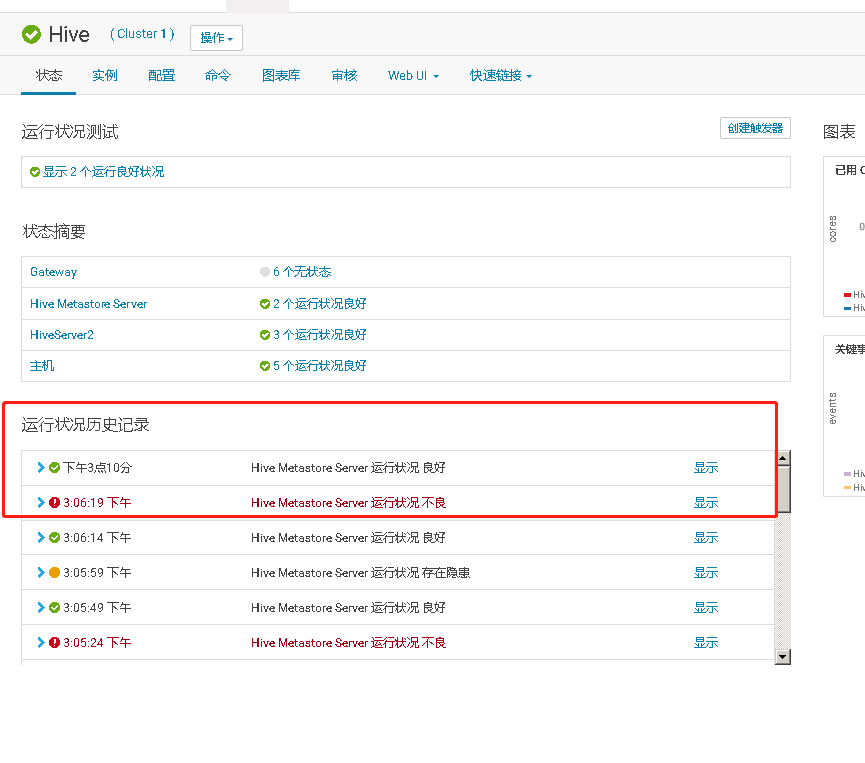
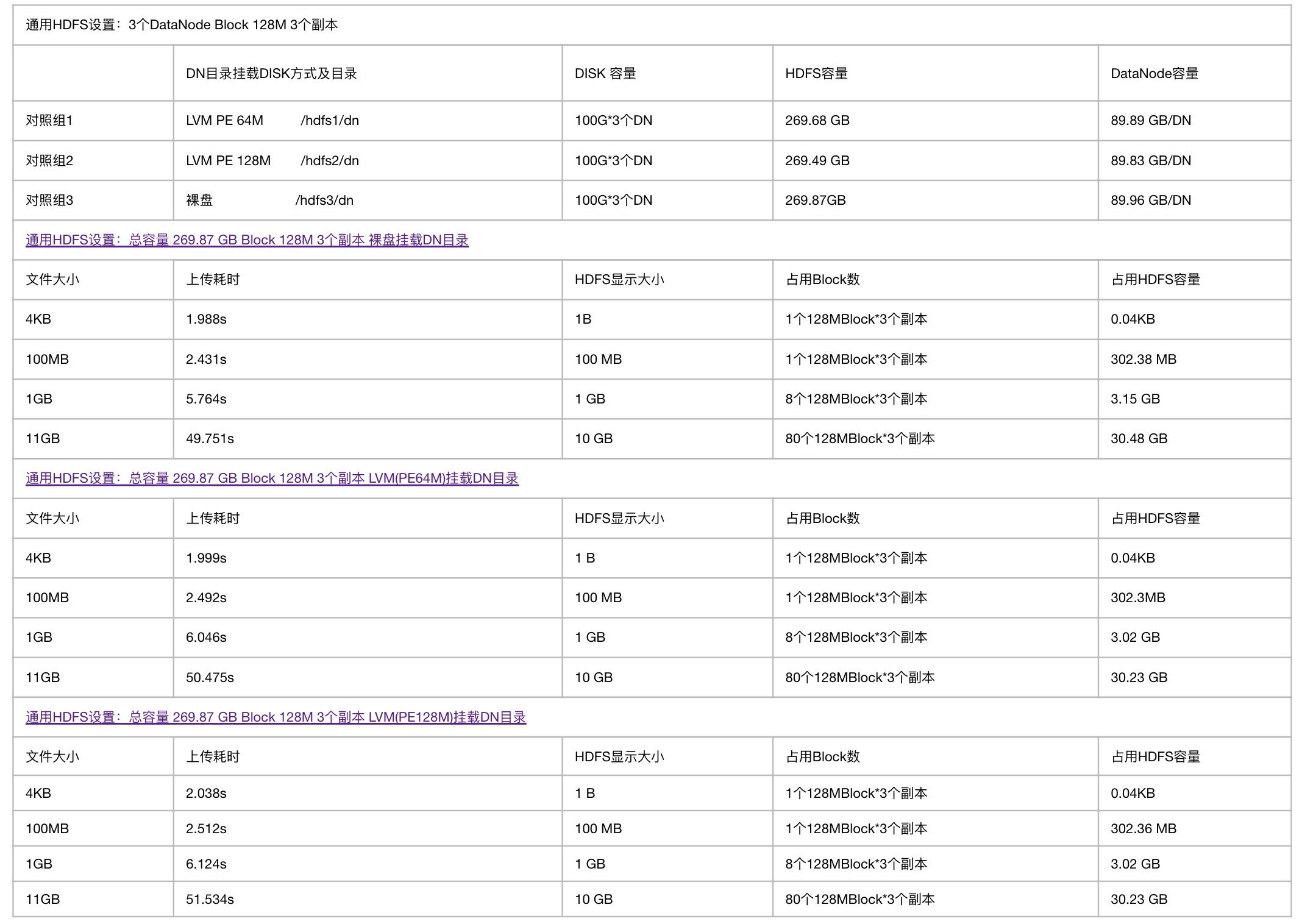
五、HDFS DN目录挂盘方式、容量与IO测试
六、HiBench基准测试框架
https://blog.csdn.net/Fighingbigdata/article/details/79468898
七、Cloudera自带基准性能测试
说明
Cloudera自带了几个基准测试,被打包在几个jar包中,例如:
- /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.11.1.jar 当不带参数调用时,会列出所有的测试程序
# sudo -u hdfs hadoop jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.11.1.jar
An example program must be given as the first argument.
Valid program names are:
aggregatewordcount: An Aggregate ed map/reduce program that counts the words in the input files.
aggregatewordhist: An Aggregate ed map/reduce program that computes the histogram of the words in the input files.
bbp: A map/reduce program that uses Bailey-Borwein-Plouffe to compute exact digits of Pi.
dbcount: An example job that count the pageview counts from a datae.
distbbp: A map/reduce program that uses a BBP-type formula to compute exact bits of Pi.
grep: A map/reduce program that counts the matches of a regex in the input.
join: A job that effects a join over sorted, equally partitioned datasets
multifilewc: A job that counts words from several files.
pentomino: A map/reduce tile laying program to find solutions to pentomino problems.
pi: A map/reduce program that estimates Pi using a quasi-Monte Carlo method.
randomtextwriter: A map/reduce program that writes 10GB of random textual data per node.
randomwriter: A map/reduce program that writes 10GB of random data per node.
secondarysort: An example defining a secondary sort to the reduce.
sort: A map/reduce program that sorts the data written by the random writer.
sudoku: A sudoku solver.
teragen: Generate data for the terasort
terasort: Run the terasort
teravalidate: Checking results of terasort
wordcount: A map/reduce program that counts the words in the input files.
wordmean: A map/reduce program that counts the average length of the words in the input files.
wordmedian: A map/reduce program that counts the median length of the words in the input files.
wordstandarddeviation: A map/reduce program that counts the standard deviation of the length of the words in the input files.
- /opt/cloudera/parcels/CDH/lib/hadoop-0.20-mapreduce/hadoop-test-2.6.0-mr1-cdh5.11.1.jar 当不带参数调用时,会列出所有的测试程序
# sudo -u hdfs hadoop jar /opt/cloudera/parcels/CDH/lib/hadoop-0.20-mapreduce/hadoop-test-2.6.0-mr1-cdh5.11.1.jar
An example program must be given as the first argument.
Valid program names are:
DFSCIOTest: Distributed i/o benchmark of libhdfs.
DistributedFSCheck: Distributed checkup of the file system consistency.
MRReliabilityTest: A program that tests the reliability of the MR framework by injecting faults/failures
TestDFSIO: Distributed i/o benchmark.
dfsthroughput: measure hdfs throughput
filebench: Benchmark SequenceFile(Input|Output)Format (block,record compressed and uncompressed), Text(Input|Output)Format (compressed and uncompressed)
loadgen: Generic map/reduce load generator
mapredtest: A map/reduce test check.
minicluster: Single process HDFS and MR cluster.
mrbench: A map/reduce benchmark that can create many small jobs
nnbench: A benchmark that stresses the namenode.
testarrayfile: A test for flat files of binary key/value pairs.
testbigmapoutput: A map/reduce program that works on a very big non-splittable file and does identity map/reduce
testfilesystem: A test for FileSystem read/write.
testmapredsort: A map/reduce program that validates the map-reduce framework's sort.
testrpc: A test for rpc.
testsequencefile: A test for flat files of binary key value pairs.
testsequencefileinputformat: A test for sequence file input format.
testsetfile: A test for flat files of binary key/value pairs.
testtextinputformat: A test for text input format.
threadedmapbench: A map/reduce benchmark that compares the performance of maps with multiple spills over maps with 1 spill
TeraSort排序
SortBenchmark(http://sortbenchmark.org/ )是JimGray自98年建立的一项排序竞技活动,它制定了不同类别的排序项目和场景,每年一次,决出各项排序算法实现的第一名(看介绍是在每年的ACM SIGMOD颁发奖牌哦)。 Hadoop在2008年以209秒的成绩获得年度TeraSort项(Dotona类)的第一名;而此前这一项排序的记录是297秒。从SortBenchmark网站上可以了解到,Hadoop到今天仍然保持了Minute项Daytona类型排序的冠军。Minute项排序是通过评判在60秒或小于60秒内能够排序的最大数据量来决定胜负的;其实等同于之前的TeraSort(TeraSort的评判标准是对1T数据排序的时间)。 SortBenchmark对排序的输入数据制定了详细规则,要求使用其提供的gensort工具(http://www.ordinal.com/gensort.html )生成输入数据。Hadoop的TeraSort也用Java实现了一个生成数据工具TeraGen,算法与gensort一致。 对输入数据的基础要求是:输入文件是由一行行100字节的记录组成,每行记录包括一个10字节的Key;以Key来对记录排序。 Minute项排序允许输入文件可以是多个文件,但Key的每个字节要求是binary编码而不是ASCII编码,也就是每个字符可能有256种可能,也就是说每条记录,有2的80次方种可能的Key; 同时Daytona类别则要求排序程序不仅是为10字节长Key、100字节长记录排序设计的,还可以支持对其他长度的Key或行记录进行排序;也就是说这个排序程序是通用的
1、生成Terasort排序数据Teragen
time sudo -u hdfs hadoop jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar teragen 200000000 /user/teragen
teragen后的数值单位是行数;因为每行100个字节,所以如果要产生1T的数据量,则这个数值应为1T/100=10000000000(10个0)。 每行记录由3段组成:
- 前10个字节:随机binary code的十个字符,为key
- 中间10个字节:行id
- 后面80个字节:8段,每段10字节相同随机大写字母
TeraGen作业没有Reduce Task,产生文件的个数取决于设定Map的个数。
2、进行Terasort排序
time sudo -u hdfs hadoop jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar terasort /user/teragen /user/terasort
运行后,我们可以看到会起m个mapper(取决于输入文件个数)和r个reducer(取决于设置项:mapred.reduce.tasks),排好序的结果存放在/user/terasort目录下 查看TeraSort的源代码,你会发现这个作业同时没有设置mapper和reducer;也就是意味着它使用了Hadoop默认的IdentityMapper和IdentityReducer。IdentityMapper和IdentityReducer对它们的输入不做任何处理,将输入k,v直接输出;也就是说是完全是为了走框架的流程而空跑。 这正是Hadoop的TeraSort的巧妙所在,它没有为排序而实现自己的mapper和reducer,而是完全利用Hadoop的Map Reduce框架内的机制实现了排序。查看TeraSort的源代码,你会发现这个作业同时没有设置mapper和reducer;也就是意味着它使用了Hadoop默认的IdentityMapper和IdentityReducer。IdentityMapper和IdentityReducer对它们的输入不做任何处理,将输入k,v直接输出;也就是说是完全是为了走框架的流程而空跑。这正是Hadoop的TeraSort的巧妙所在,它没有为排序而实现自己的mapper和reducer,而是完全利用Hadoop的Map Reduce框架内的机制实现了排序。
3、排序结果的校验TeraValidate
time sudo -u hdfs hadoop jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar teravalidate /user/terasort /user/terasortvalidate
需要一提的是TeraValidate的作业配置里有这么一句:
job.setLong("mapred.min.split.size", Long.MAX_VALUE);
它用来保证每一个输入文件都不会被split,又因为TeraInputFormat继承自FileInputFormat,所以TeraValidate运行mapper的总数正好等于输入文件的个数。
TestDFSIO测试
TestDFSIO用于测试HDFS的IO性能,使用一个MapReduce作业来并发地执行读写操作,每个map任务用于读或写每个文件,map的输出用于收集与处理文件相关的统计信息,reduce用于累积统计信息,并产生summary。
0、TestDFSIO的用法如下:
TestDFSIO.0.0.6
Usage: TestDFSIO [genericOptions] -read | -write | -append | -clean [-nrFiles N] [-fileSize Size[B
1、向HDFS中写入文件
#往HDFS中写入10个1000MB的文件,文件在HDFS中的路径:/benchmarks/TestDFSIO
sudo -u hdfs hadoop jar /opt/cloudera/parcels/CDH/lib/hadoop-0.20-mapreduce/hadoop-test-2.6.0-mr1-cdh5.11.1.jar TestDFSIO -write -nrFiles 10 -fileSize 1000
测试结果:
18/08/15 16:57:12 INFO fs.TestDFSIO: ----- TestDFSIO ----- : write
18/08/15 16:57:12 INFO fs.TestDFSIO: Date & time: Wed Aug 15 16:57:12 CST 2018
18/08/15 16:57:12 INFO fs.TestDFSIO: Number of files: 10
18/08/15 16:57:12 INFO fs.TestDFSIO: Total MBytes processed: 1000.0
18/08/15 16:57:12 INFO fs.TestDFSIO: Throughput mb/sec: 86.89607229753216
18/08/15 16:57:12 INFO fs.TestDFSIO: Average IO rate mb/sec: 94.8116455078125
18/08/15 16:57:12 INFO fs.TestDFSIO: IO rate std deviation: 25.014017966950007
18/08/15 16:57:12 INFO fs.TestDFSIO: Test exec time sec: 13.852
18/08/15 16:57:12 INFO fs.TestDFSIO:
2、从HDFS中读取测试数据
#从HDFS中读取5个1000MB的文件,读取测试结果文件在HDFS中的路径:/benchmarks/TestDFSIO/io_read
sudo -u hdfs hadoop jar /opt/cloudera/parcels/CDH/lib/hadoop-0.20-mapreduce/hadoop-test-2.6.0-mr1-cdh5.11.1.jar TestDFSIO -read-nrFiles 5 -fileSize 1000
测试结果:
18/08/15 18:15:21 INFO fs.TestDFSIO: ----- TestDFSIO ----- : read
18/08/15 18:15:21 INFO fs.TestDFSIO: Date & time: Wed Aug 15 18:15:21 CST 2018
18/08/15 18:15:21 INFO fs.TestDFSIO: Number of files: 5
18/08/15 18:15:21 INFO fs.TestDFSIO: Total MBytes processed: 5000.0
18/08/15 18:15:21 INFO fs.TestDFSIO: Throughput mb/sec: 137.50240629211012
18/08/15 18:15:21 INFO fs.TestDFSIO: Average IO rate mb/sec: 137.68557739257812
18/08/15 18:15:21 INFO fs.TestDFSIO: IO rate std deviation: 5.010354585493878
18/08/15 18:15:21 INFO fs.TestDFSIO: Test exec time sec: 38.621
18/08/15 18:15:21 INFO fs.TestDFSIO:
3、删除测试数据
sudo -u hdfs hadoop jar /opt/cloudera/parcels/CDH/lib/hadoop-0.20-mapreduce/hadoop-test-2.6.0-mr1-cdh5.11.1.jar TestDFSIO -clean